
前言
大模型越发成熟,很多企业会尝试找到自己合适的模型进行微调和训练,最终生成一个企业AI机器人,能够帮助企业大幅提升竞争力和生产力。未来通过更好的算法研发出新的基础模型这类算法程序员固然吃香,而学习如何利用基础模型结合企业内部数据进行微调和训练的能力也显得尤为重要。
关于微调和向量
在如今的数据驱动时代,大型语言模型(LLM)如GPT等已经在各种应用场景中显示出其强大的能力,从聊天机器人到自动文本生成。然而,当涉及到特定行业领域的知识学习时,通用的LLM往往不能完全满足需求。特定行业(如医疗、法律、金融等)有其专有术语和上下文,这些通常不在通用LLM的训练数据中。因此,如何使LLM具有行业特定的知识和应用能力成为了一个迫切需要解决的问题。
基础概念
微调(Finetune):微调是一种让预先训练好的模型适应特定任务或数据集的方法。在这种情况下,一个已经训练好的大型语言模型会进一步在行业特定的数据集上进行训练。
向量数据库(Vector Database):向量数据库是一种存储特定信息和知识的数据库,可以在运行时与LLM合作,为其提供行业特定的信息。这通常通过嵌入(存储)向量(embedding vectors)来实现,这些向量可以表示文本、概念或任何其他类型的数据。
主体解决方案
在行业特定的大型语言模型(LLM)知识学习方面,有两个主要的解决方案:大模型微调(Finetune)和向量数据库(Vector Database)知识存储。
微调方案涉及在特定行业数据集上进一步训练一个预先训练好的LLM,使其更好地理解和应用行业专有术语和概念。这种方法在模型理解和生成连贯文本方面表现优越,但需要大量的计算资源和高质量的数据集。
另一方面,向量数据库方案则是通过在运行时与一个存储有行业特定信息的数据库进行交互,来丰富LLM的应用范围。这种方法在动态更新和资源效率方面有优势,但可能会增加运行时的延迟和系统复杂性。
OpenAI也针对这两种方案给出了自己的见解:Question answering using embeddings-based search
微调(Finetune)的优缺点
优点
上下文理解:微调模型会更好地理解行业特定的术语和概念,从而能更精准地解答相关问题。
连贯性和一致性:由于模型是在特定的数据集上训练的,因此其生成的文本将更加连贯和一致。
缺点
高成本和资源消耗:微调过程通常需要大量的计算资源和时间。
数据依赖性:模型的效能高度依赖于用于微调的数据集的质量。
向量数据库(Vector Database)的优缺点
优点
动态更新:向量数据库可以更容易地进行更新和维护。
资源效率:与微调相比,使用向量数据库通常需要较少的计算资源。
缺点
运行时延迟:数据库查询可能会增加处理时间。
复杂性:需要维护一个额外的数据库,并确保它与LLM良好地集成。
综合建议
混合使用:对于需要即时更新信息的应用场景,推荐使用微调和向量数据库的混合方法。
数据质量:无论选择哪种方法,都应确保使用的数据集具有高质量和可靠性。
性能考量:如果资源有限,向量数据库可能是一个更经济、更灵活的选择。
总结
行业特定的LLM知识学习是一个复杂但重要的课题。通过微调和使用向量数据库,我们可以让LLM更好地适应特定行业的需求。选择哪一种方法取决于多种因素,包括数据质量、可用资源和特定应用的需求。
基础模型选择和加载方案
优秀的模型有很多,具体可以看SuperCLUE的最新榜单,列出了通用中文大模型的排行。
其中最好的国外大模型社区huggingface,网站https://huggingface.co/
国内魔塔社区,网站https://modelscope.cn/models
都可以尝试体验基础模型或通过分享的模型
从榜单中,我们选择了开源的Chatglm2-6B,Llama2-7B做单机部署测试
使用Langchain加载大模型是一种简单快捷的大模型对话的部署方案,其中有开源项目LangChain-Chatchat(项目地址:https://github.com/chatchat-space/Langchain-Chatchat),一种利用 langchain 思想实现的基于本地知识库的问答应用,目标期望建立一套对中文场景与开源模型支持友好、可离线运行的知识库问答解决方案。
LangChain-Chatchat 使用 FastChat 进行本地 LLM 模型接入,支持众多模型;同时支持调用 HuggingFace 中的 Embedding 模型。
通过配置文件配置大模型路径,Embedding模型路径即可快速搭建基于streamlit的web界面进行问答。
环境
部署环境
操作系统:Ubuntu 22.04
CPU:Intel I7-10700
内存:DDR4 16G
显卡:RTX 3090 24G 公版
存储:SSD 500G
安装显卡驱动和CUDA软件
安装完Ubuntu后会安装Nvidia显卡驱动,但没有安装CUDA,先运行nvidia-smi来取得该显卡支持的CUDA版本
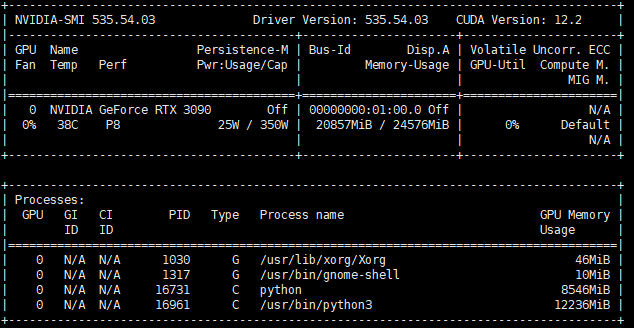
这里看到该驱动支持的CUDA版本为122,然后到官网下载:https://developer.nvidia.com/cuda-toolkit-archive
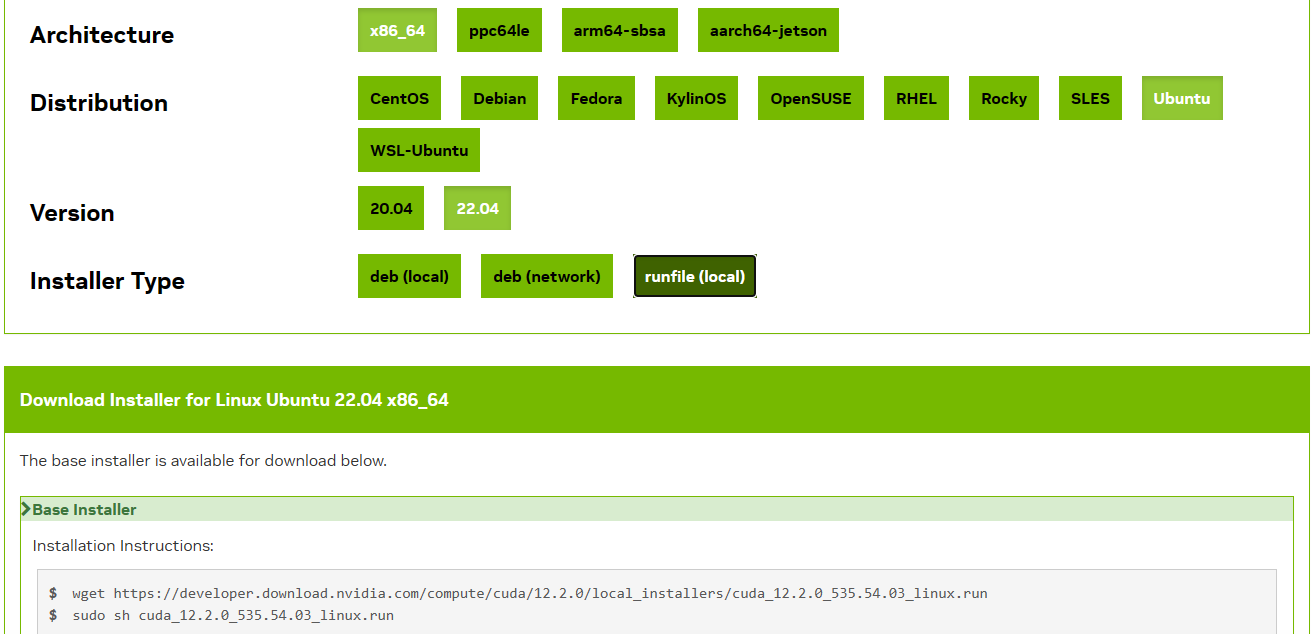
运行对应的命令即可,运行时只选择CUDA软件即可,不用选择安装驱动。
安装完毕后,运行:python -c "import torch; print(torch.cuda.is_available());"
来确认CUDA是否可用,如果显示True则正常。
安装Anaconda
conda (https://docs.conda.io/en/latest/) 是由 Anaconda 开发的开源跨平台语言无关的包管理器。它用于安装各种包,可以用于Python,R,Ruby,Lua,Scala,Java,JavaScript,C/ C++,FORTRAN等等,尽管Python是最常见的使用情况。
同时,conda也是一个环境管理系统,用于在同一机器上创建有不同Python版本或包集合的隔离环境。
conda在大数据科学、机器学习、深度学习和相关领域特别受欢迎,这是因为它能很好地处理具有复杂依赖关系的大型科学计算包,比如NumPy,SciPy,Pandas等。
conda的优点之一是它的跨平台性,它可以在Windows,macOS和Linux上运行。此外,conda也支持二进制包,这意味着在安装包时无需从源代码编译,这通常比使用Python的默认包管理器pip更快,更容易。
1.下载Anaconda
下载地址:https://mirrors.tuna.tsinghua.edu.cn/anaconda/archive/?C=M&O=D
选择合适的版本下载到本地,本次下载了Anaconda3-2023.07-2-Linux-x86_64.sh,再通过lrzsz工具或者winscp上传到主机
2、安装Anacondasudo chmod a+x Anaconda3-2023.07-2-Linux-x86_64.shsh Anaconda3-2023.07-2-Linux-x86_64.sh
3、启动环境
默认Anaconda安装到/home/xxx/anaconda3目录下(xxx为当前用户)
运行source ~/.bashrc进入了base环境
4、conda常用命令
创建环境:conda create -n 环境名
激活环境:conda activate 环境名
显示所有已经创建的环境:conda info -e或conda env list
删除环境:conda remove --name 环境名 --all
其他,参考https://www.cnblogs.com/ghj1976/p/venv-vs-conda.html
部署大模型
ChatGLM2-6B
https://github.com/THUDM/ChatGLM2-6B
Llama
https://github.com/FlagAlpha/Llama2-Chinese
部署大模型LLaMA/Qwen-7B的过程中,需要安装量化工具包bitsandbytes,在conda python环境下,通过pip install bitsandbytes直接安装,或是按源码编译安装,在python -m bitsandbytes检测时均出现异常,
问题解决
在环境变量LD_LIBRARY_PATH中增加CUDA的lib路径:export PATH=/usr/local/cuda-12.2/bin:$PATHexport LD_LIBRARY_PATH=/usr/local/cuda-12.2/lib64:$LD_LIBRARY_PATH
然后重新安装bitsandbytes即可:pip uninstall bitsandbytespip install bitsandbytes
Lang-Chain
参考项目地址:https://github.com/chatchat-space/Langchain-Chatchat
model.py配置:
1 | (base) tbk@LLM-PC:/app/Langchain-Chatchat$ vim configs/model_config.py |
最后运行sudo python startup.py -a,出现地址和端口复制到浏览器访问即可
大模型知识搬运
1、大模型介绍和概述:
LLMs模型速览(GPTs、LaMDA、GLM/ChatGLM、PaLM/Flan-PaLM、BLOOM、LLaMA、Alpaca)
2、最新最全AI大模型资料和仓库:
AI大模型列表
3、行业特定的LLM知识学习课题:
微调(Finetune)与向量数据库(Vector Database)的比较与应用
4、AIGC基础知识杂谈:大模型、多模态、预训练、扩散模型:
大模型、多模态、预训练、扩散模型等基础理论
5、部署ChatGPT3.5需要的硬件成本:
GPT-3.5(ChatGPT)训练和部署成本估算