
Prometheus介绍
Prometheus是一个最初在SoundCloud上构建的开源监控系统 。它现在是一个独立的开源项目,为了强调这一点,并说明项目的治理结构,Prometheus 于2016年加入CNCF,作为继Kubernetes之后的第二个托管项目。
Prometheus是由SoundCloud开发的开源监控报警系统和时序列数据库。从字面上理解,Prometheus由两个部分组成,一个是监控报警系统,另一个是自带的时序数据库(TSDB)
特点
- 具有由 metric 名称和键/值对标识的时间序列数据的多维数据模型
- PromQL,有一个灵活的查询语言
- 不依赖分布式存储,只和本地磁盘有关
- 通过 HTTP 的服务拉取时间序列数据
- 也支持推送的方式来添加时间序列数据
- 通过服务发现或静态配置发现目标
- 多种图形和仪表板支持
架构图
此图说明prometheus的体系结构及其一些系统组件
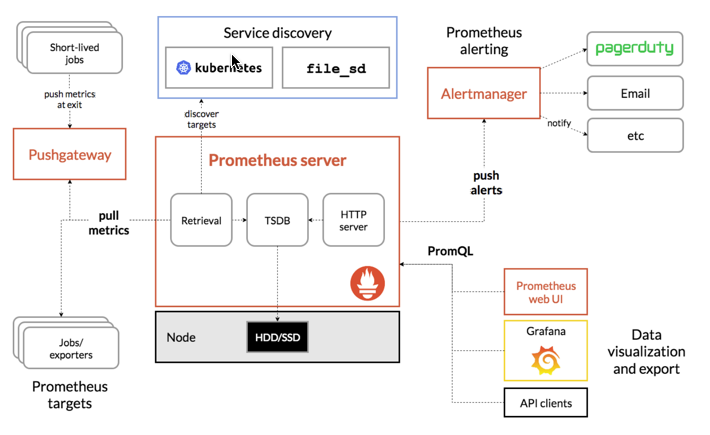
图片左侧是各种数据源主要是各种符合 Prometheus 数据格式的 exporter,除此之外为了支持推动数据 类型的 Agent,可以通过 Pushgateway 组件,将 Push 转化为 Pull。Prometheus 甚至可以从其它的 Prometheus 获取数据,组建联邦集群。Prometheus 的基本原理是通过 HTTP 周期性抓取被监控组件的状态,任意组件只要提供对应的 HTTP 接口 并且符合 Prometheus 定义的数据格式,就可以接入 Prometheus 监控。
图片的上侧是服务发现,Prometheus 支持监控对象的自动发现机制,从而可以动态获取监控对象。 图片中间是 Prometheus Server,Retrieval 模块定时拉取数据,并通过 Storage 模块保存数据。PromQL 为 Prometheus 提供的查询语法,PromQL 模块通过解析语法树,调用 Storage 模块查询接口获取监控数据。 图片右侧是告警和页面展现,Prometheus 将告警推送到 alertmanger,然后通过 alertmanger 对告警进行处 理并执行相应动作。数据展现除了 Prometheus 自带的 webui,还可以通过 grafana 等组件查询 Prometheus 监控数据。
与其他监控系统的比较
在Prometheus 之前市面已经出现了很多的监控系统,如 Zabbix、Open-falcon 等。那么 prometheus 和这些监控系统有啥异同呢?我们先简单介绍一下这些监控系统
Zabbix 是由 Alexei Vladishev 开源的分布式监控系统,支持多种采集方式和采集客户端,同时支持 SNMP、 IPMI、JMX、Telnet、SSH 等多种协议,它将采集到的数据存放到数据库中,然后对其进行分析整理,如果 符合告警规则,则触发相应的告警。
Zabbix 核心组件主要是 Agent 和 Server,其中 Agent 主要负责采集数据并通过主动或者被动的方式采集数据发送到 Server/Proxy,除此之外,为了扩展监控项,Agent 还支持执行自定义脚本。Server 主要负责 接收 Agent 发送的监控信息,并进行汇总存储,触发告警等。为了便于快速高效的配置 zabbix 监控项,zabbix 提供了模板机制,从而实现批量配置的目的。
Zabbix Server 将收集的监控数据存储到 Zabbix Database 中。Zabbix Database 支持常用的关系型 数据库,如果 MySQL、PostgreSQL、Oracle 等,默认 是 MySQL。Zabbix Web 页面(PHP 编写)负责数据 查询。Zabbix 由于使用了关系型数据存储时序数据,所以在监控大规模集群时常常在数据存储方面捉襟见 肘。为此 zabbix 4.2 版本后也开始支持时序数据存储,不过目前还不成熟。
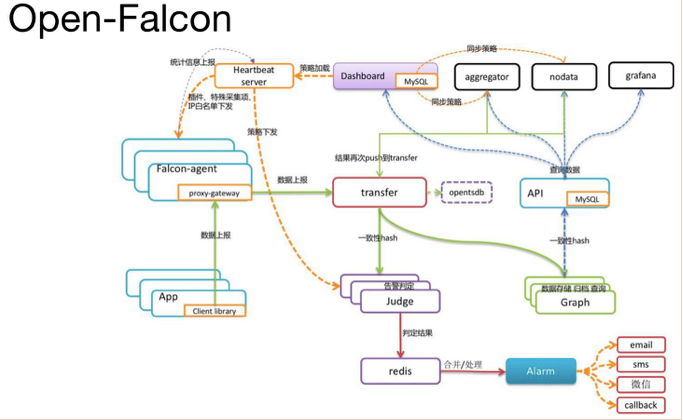
Open-Falcon 是小米开源的企业级监控工具,用 Go 语言开发而成,包括小米、滴滴、美团等在内的互 联网公司都在使用它,是一款灵活、可扩展并且高性能的监控方案,主要组件包括:
Falcon-agent:用 Go 语言开发的 Daemon 程序,运行在每台 Linux 服务器上,用于采集主机上的各种 指标数据,主要包括 CPU、内存、磁盘、文件系统、内核参数、Socket 连接等,目前已经支持 200 多项监 控指标。并且,Agent 支持用户自定义的监控脚本,
Hearthbeat server:简称 HBS 心跳服务,每个 Agent 都会周期性地通过 RPC 方式将自己的状态上报给 HBS,主要包括主机名、主机 IP、Agent 版本和插件版本,Agent 还会从 HBS 获取自己需要执行的采集任务 和自定义插件。
Transfer:负责接收 Agent 发送的监控数据,并对数据进行整理,在过滤后通过一致性 Hash 算法发送 到 Judge 或者 Graph
Graph:RRD 数据上报、归档、存储的组件。Graph 在收到数据以后,会以 rrdtool 的数据归档方式来存 储,同时提供 RPC 方式的监控查询接口。
Judge:告警模块,Transfer 转发到 Judge 的数据会触发用户设定的告警规则,如果满足,则会触发邮 件、微信或者回调接口。这里为了避免重复告警引入了 Redis 暂存告警,从而完成告警的合并和抑制。
Dashboard:面向用户的监控数据查询和告警配置界面
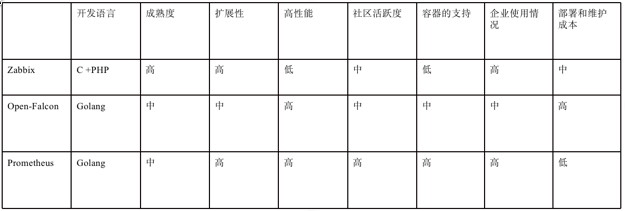
从开发语言上看,为了应对高并发和快速迭代的需求,监控系统的开发语言已经慢慢从 C 语言转移到 Go。不得不说,Go 凭借简洁的语法和优雅的并发,在 Java 占据业务开发,C 占领底层开发的情况下,准确 定位中间件开发需求,在当前开源中间件产品中被广泛应用。
从系统成熟度上看,Zabbix 是老牌的监控系统:Zabbix 是在 1998 年出现的,系统功能比较稳定,成熟 度较高。而 Prometheus 和 Open-Falcon 都是最近几年才诞生的,虽然功能还在不断迭代更新,但站在巨人 的肩膀之上,在架构设计上借鉴了很多老牌监控系统的经验;
从系统扩展性方面看,Zabbix 和 Open-Falcon 都可以自定义各种监控脚本,并且 Zabbix 不仅可以做到 主动推送,还可以做到被动拉取,Prometheus 则定义了一套监控数据规范,并通过各种 exporter 扩展系统 采集能力;
从数据存储方面来看,Zabbix 采用关系数据库保存,这极大限制了 Zabbix 采集的性能,Open-Falcon 采用 RDD 数据存储,并且可以对接到 OpenTSDB,而 Prometheus 自研一套高性能的时序数据库,在 V3 版 本可以达到每秒千万级别的数据存储,通过对接第三方时序数据库扩展历史数据的存储;
从配置和维护的复杂度上看,prometheus 只有一个核心 server 组件,一条命令便可以启动,相比而言, 其他系统配置相对麻烦,尤其是 open-falcon。
从社区活跃度上看,目前 Zabbix 社区活跃度比较低,Open-Falcon 虽然也比较活跃,但基本都是国内 的公司参与,Prometheus 在这方面占据绝对优势,社区活跃度最高,并且受到 CNCF 的支持,后期的发展 值得期待;
从容器支持角度看,由于 Zabbix 出现得比较早,当时容器还没有诞生,自然对容器的支持也比较差。 Open-Falcon 虽然提供了容器的监控,但支持力度有限。Prometheus 的动态发现机制,不仅可以支持 swarm 原生集群,还支持 Kubernetes 容器集群的监控,是目前容器监控最好解决方案。Zabbix 在传统监控系统中, 尤其是在服务器相关监控方面,占据绝对优势。伴随着容器的发展,Prometheus 开始成为主导及容器监控 方面的标配,并且在未来可见的时间内被广泛应用。总体来说,对比各种监控系统的优劣,Prometheus 可 以说是目前监控领域最锋利的“瑞士军刀”了。
使用docker搭建监控linux主机
可以参考官方方法:https://prometheus.io/docs/guides/node-exporter/
可以知道,监控linux主机需要node-exporter,所以docker镜像需要node-exporter,prometheus,grafana
拉取镜像
docker pull prom/node-exporterdocker pull prom/prometheusdocker pull grafana/grafana
启动node-exporter
node_exporter设计用于监控主机系统。不建议将其部署为Docker容器,因为它需要访问主机系统。请注意,您要监视的任何非根安装点都需要绑定到容器中。如果启动容器以进行主机监视,请指定path.rootfs参数。此参数必须与host root的bind-mount中的路径匹配。node_exporter将path.rootfs用作访问主机文件系统的前缀。
1 | cat > run_node_exporter.sh << EOF |
启动后访问http://IP:9100/metrics,正常会显示:
这些都是收集到数据,有了它就可以做数据展示了
启动prometheus
新建目录prometheus,编辑配置文件prometheus.yml:mkdir -p prometheus/confvim prometheus/conf/prometheus.yml
1 | global: |
IP修改为自己服务器IP,其他名字如job_name可以自行修改,如果要监控多台服务器,则在targets里面添加
参考官方配置:https://prometheus.io/docs/prometheus/latest/configuration/configuration/
修改目录权限,默认prometheus使用nobody的内置用户,对应UID为65534:chown -R 65534.root prometheuschmod -R 775 prometheus
启动container:docker run -d -p 9090:9090 -v /app/prometheus/conf:/etc/prometheus -v /app/prometheus:/prometheus prom/prometheus --web.enable-lifecycle
“—web.enable-lifecycle” 参数是运行prometheus热加载配置文件,运行curl -X POST http://ip:port/-/reload来重载配置
container默认配置文件在/etc/prometheus/prometheus.yml
启动后访问:http://IP:9090/graph,正常显示:
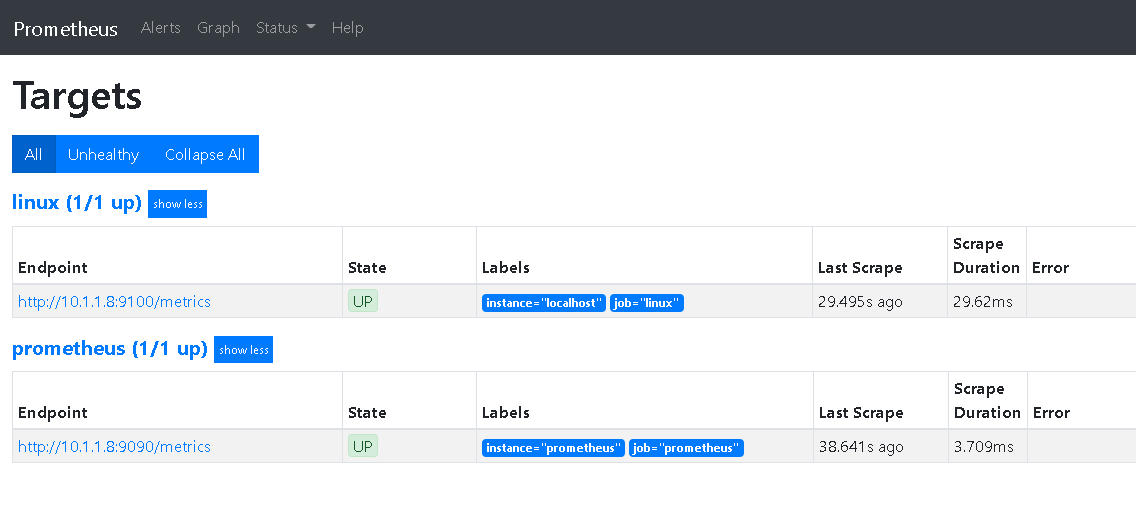
访问targets,http://IP:9090/targets,正常显示:
启动grafana
参考官方配置:https://grafana.com/docs/grafana/latest/installation/docker/
新建目录来存储grafana的数据:mkdir -p grafana/{data,logs}
修改目录权限,默认grafana使用用户grafana,对应UID为472:chown -R 472.root grafanachmod -R 775 grafana
启动container:docker run -d -p 3000:3000 --name=grafana -v /app/grafana/data:/var/lib/grafana -v /app/grafana/logs:/var/log/grafana grafana/grafana
访问URL:http://IP:3000
默认用户名和密码都是admin,首次登录需要修改密码,密码设置完成之后,就会跳转到首页,点击Add data source,由于使用的是镜像方式Prometheus:
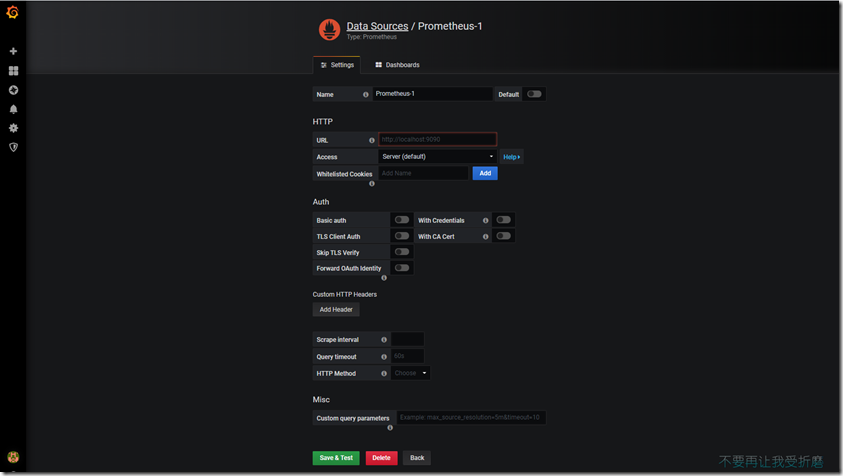
name名字写Prometheus,type 选择Prometheus,因为数据都从它那里获取,url 输入Prometheus的ip+端口,点击下面的Save & Test,如果出现绿色的,说明ok了。
使用grafana 的仪表盘模板导入ID=8919的仪表盘 ,点击 import导入即成功 (如果是docker监控模板推荐 8321)
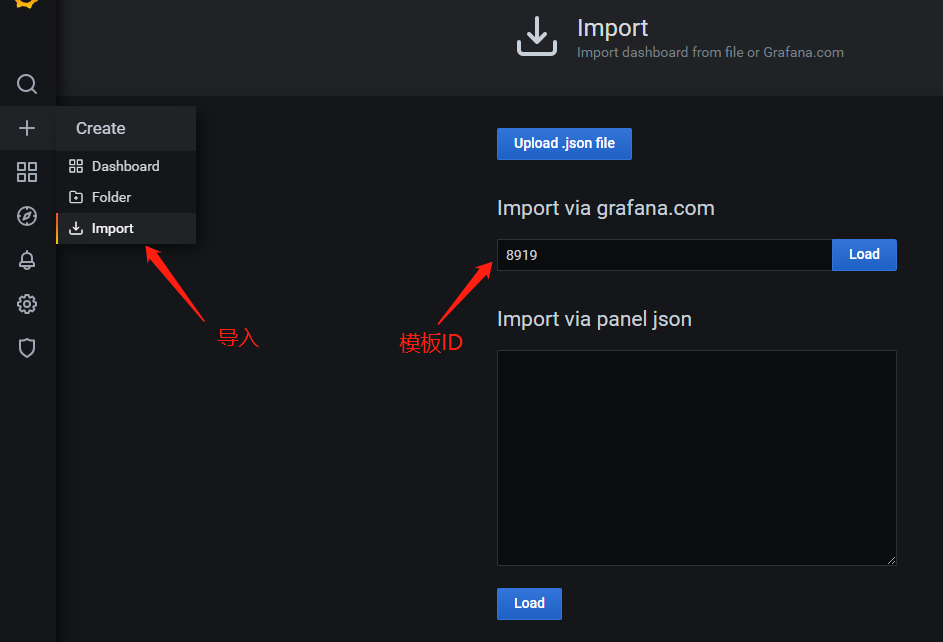
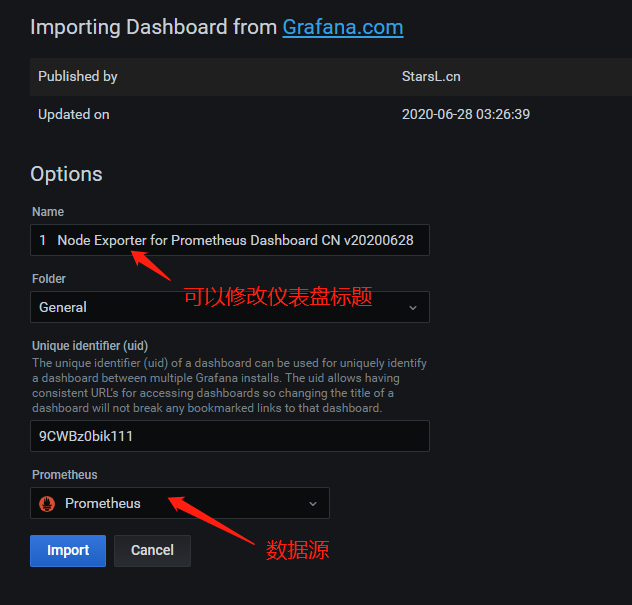
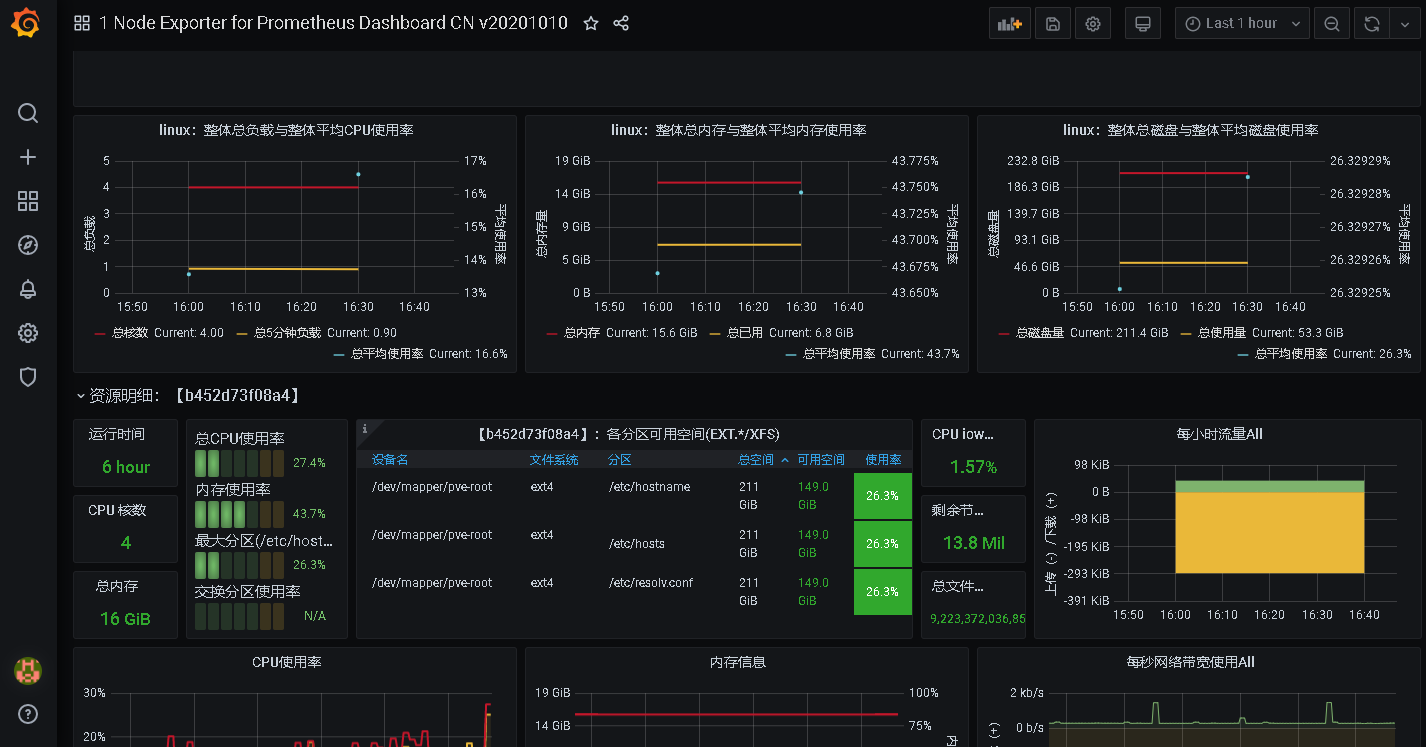
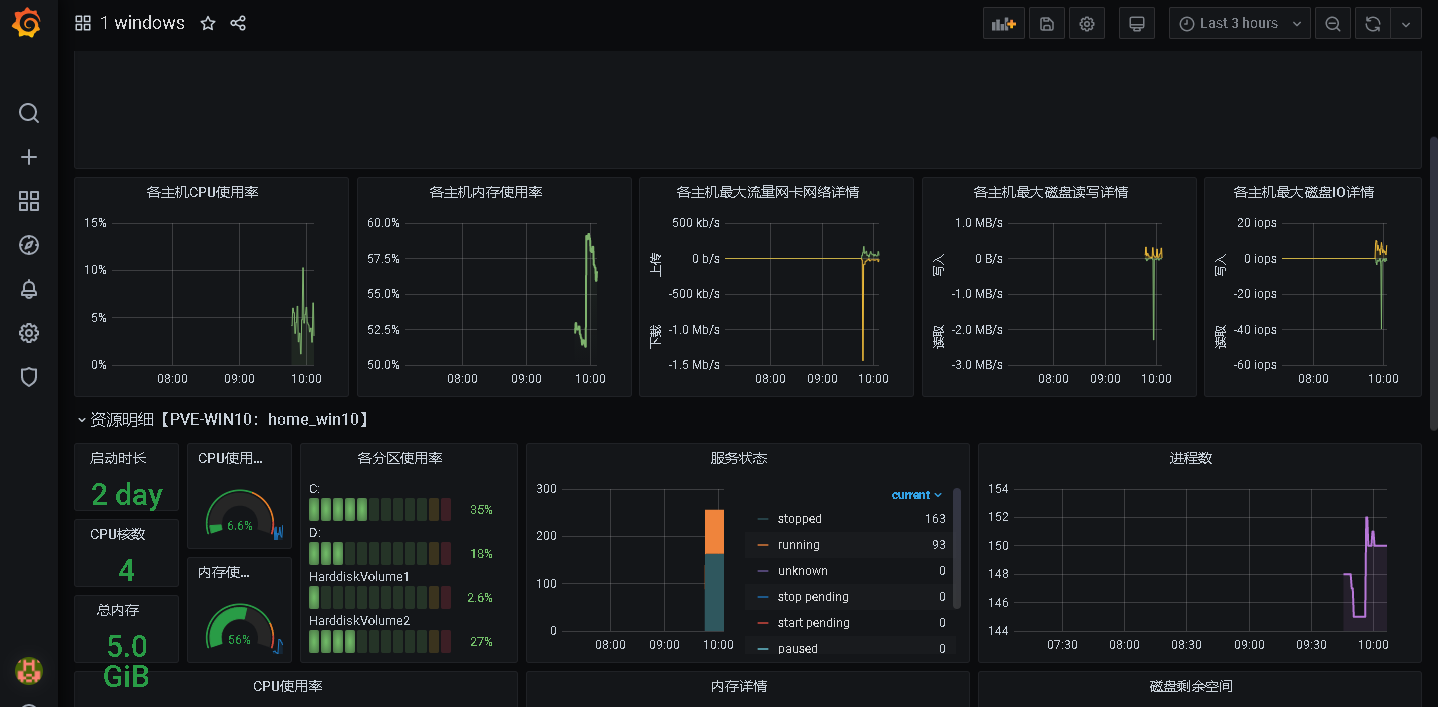
导入后效果:
监控windows主机
node-exporter是监控linux主机使用的,官方没有监控windows的插件,可以从https://github.com/prometheus-community/windows_exporter/releases下载
下载后双击安装即可,默认端口为9182,然后访问http://IP:9182,会出现跟node-exporter一样的页面,然后修改prometheus.yml文件,添加windows主机的监控项:
1 | global: |
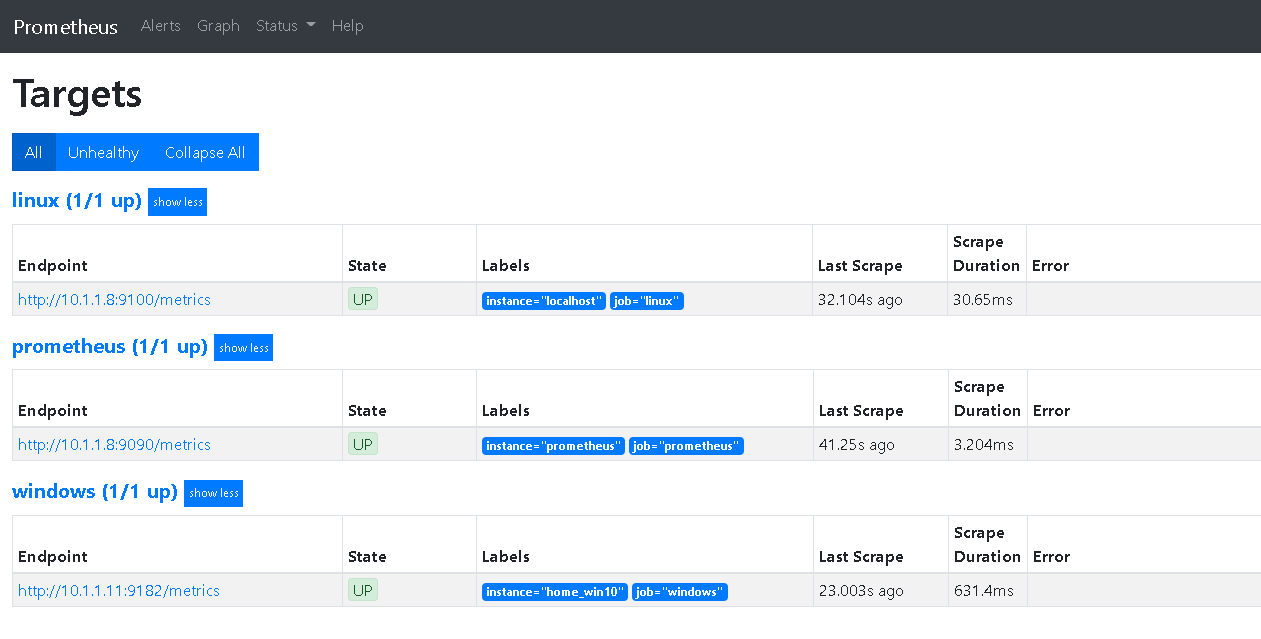
重启prometheus的容器,此时再次访问http://IP:9090/targets,可以看到会多一个endpoint,就是刚配置上去的windows主机
回到grafana的dashboard市场https://grafana.com/grafana/dashboards,搜索windows,找到dashboard的ID
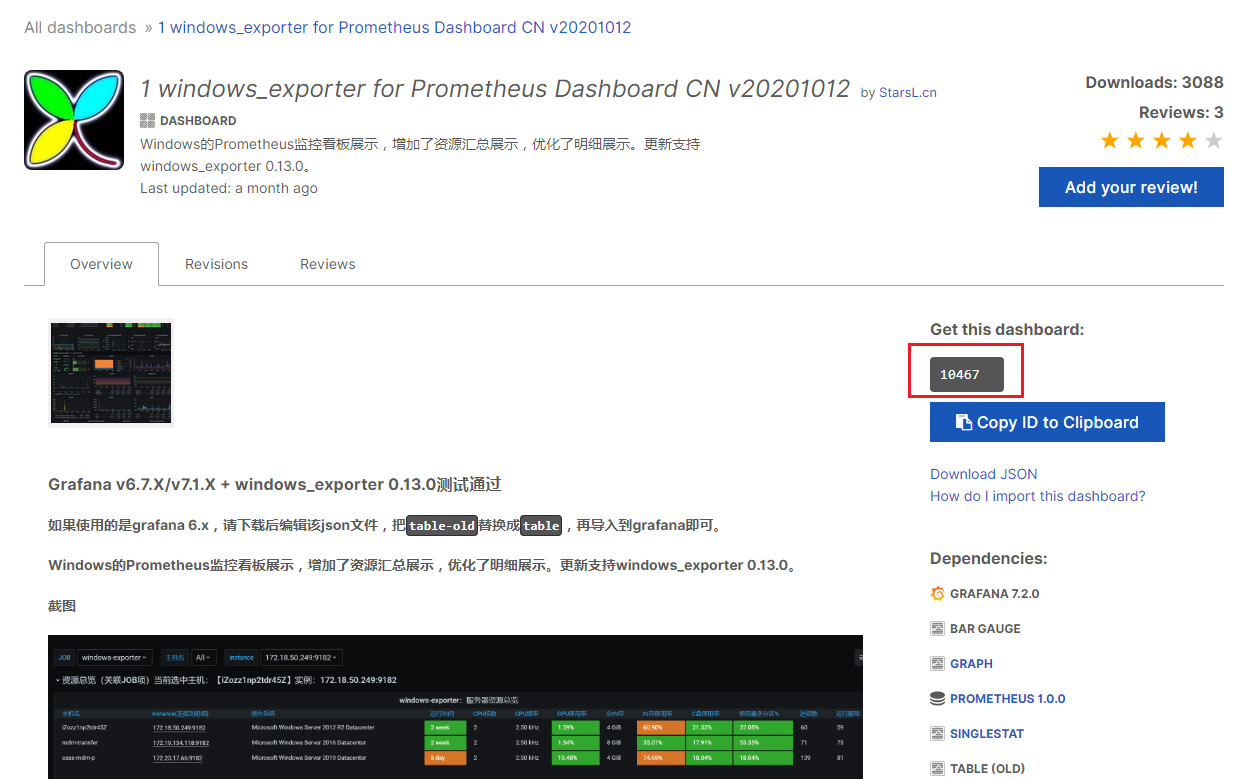
最后重复跟linux一样的导入操作即可
监控docker
使用docker镜像google/cadvisor,配置参考https://github.com/google/cadvisor
配置完毕后访问http://ip:设置端口可以查看网页:

其他跟监控windows一样,修改prometheus配置文件,新增一项job_name:
1 |
|
模板可以直接搜cadvisor
grafana忘记登录密码
- 参考官方方法:https://grafana.com/docs/grafana/latest/administration/cli/#reset-admin-password
进入grafana的container
运行:grafana-cli admin reset-admin-password xxx
- google方法:
找到grafana的数据文件grafana.db
进入数据库,如:sqlite3 /var/lib/grafana/grafana.db
查看表:
.table
查看表数据:select * from user;
更改密码为admin:update user set password = '59acf18b94d7eb0694c61e60ce44c110c7a683ac6a8f09580d626f90f4a242000746579358d77dd9e570e83fa24faa88a8a6', salt = 'F3FAxVm33R' where login = 'admin';
退出:
.exit
更改后,会重置密码为admin
使用grafana内置的报警
grafana内置alertmanager插件,可以通过邮件,钉钉或其他接口来发送报警,但是发送的内容比较简单,可编辑性也不高,但是日常收监控警报已经够用了。grafana设置报警非常人性化,按照页面一步步填写完毕即可。
设置警报规则
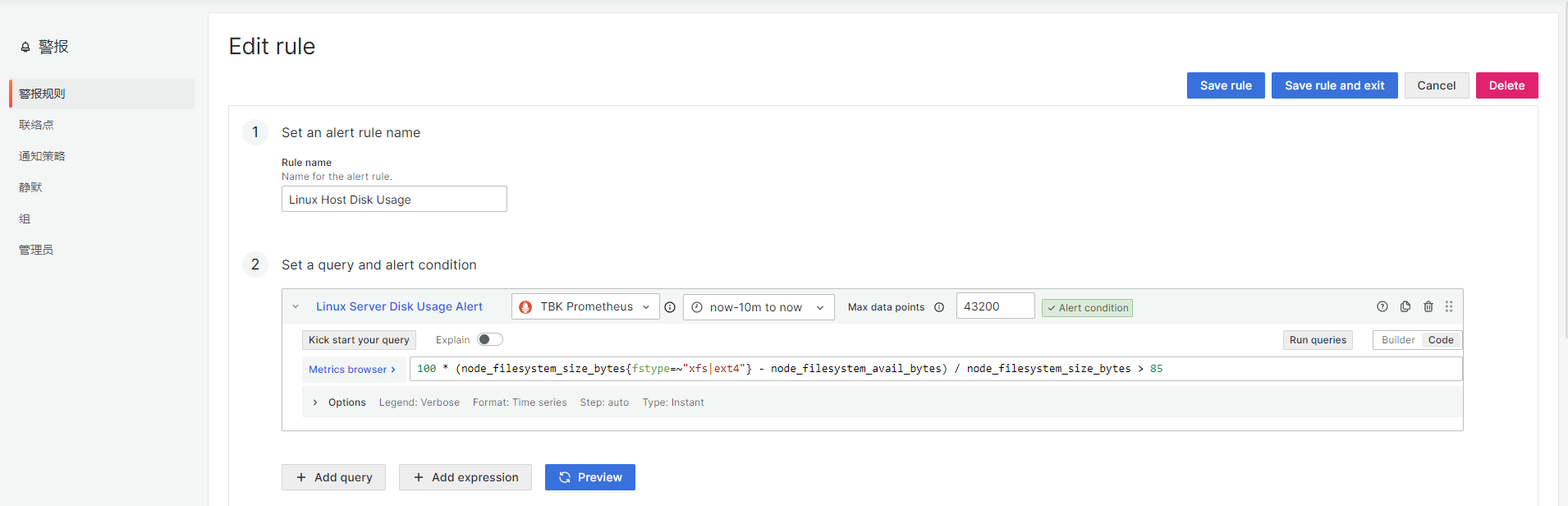
第一第二步,设置规则名称和请求警报条件,其中默认A为请求名称,可以修改,Metrics browser里面可以查看所有支持的值,请求可以使用builder模式和code模式,一般使用code模式自定义请求,其他设置默认即可。这里设置了linux的磁盘警报:
100 * (node_filesystem_size_bytes{fstype=~"xfs|ext4"} - node_filesystem_avail_bytes) / node_filesystem_size_bytes > 85
检测所有xfs和ext4格式的磁盘,如果使用率大于85%则报警。
如果设置windows报警,根据仪表板,会多出一个hardvolule1的磁盘,此时可以通过仪表板配置一下这个图表的Metrics来忽略这个磁盘:
100 - (windows_logical_disk_free_bytes{job=~"$job",instance=~"$instance",volume=~".:"} / windows_logical_disk_size_bytes{job=~"$job",instance=~"$instance",volume=~".:"})*100
volume=~”.:”就是使用正则匹配,只显示分区盘符即可。
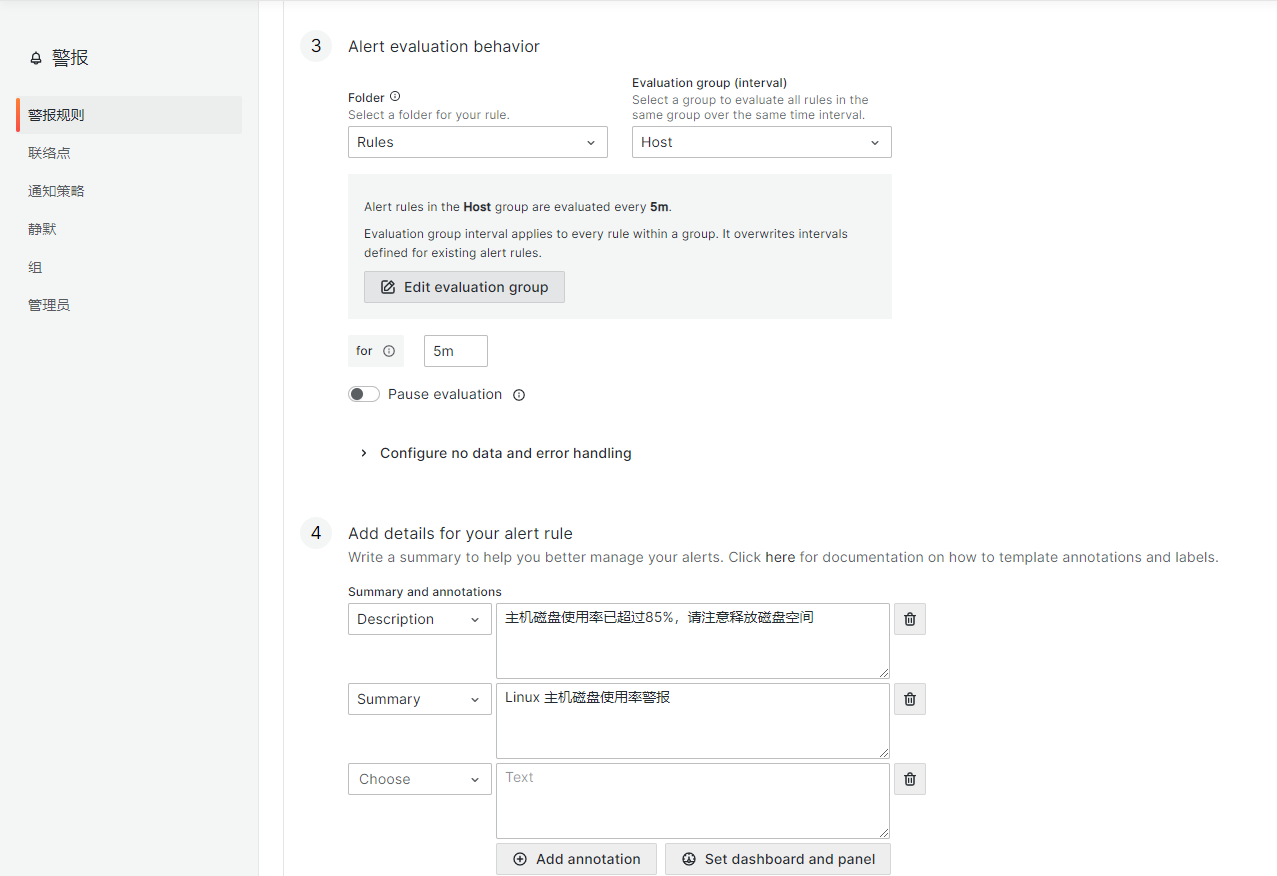
第三第四步,设置警报的评估行为和警报详细信息,其中第三步有个Configure no data and error handling,也就是当没有匹配到警报信息的时候,可以显示OK。
第五步配置通知选项,默认是通过根路由来进行。
设置联络点
就是设置通知方式
设置通知策略
设置好通知方式,这里默认即可
其他常用的报警请求
CPU使用率
100 * (1 - avg(irate(node_cpu_seconds_total{mode="idle"}[2m])) by(instance)) > 10
模拟提高CPU使用率可以使用命令cat /dev/urandom | md5sum
内存使用率
(node_memory_MemTotal_bytes - node_memory_MemAvailable_bytes) / node_memory_MemTotal_bytes * 100 > 20
模拟提高内存使用率可以参考:https://blog.csdn.net/heavenmark/article/details/82805260 恢复内存就重启机器吧
参考出处
https://www.cnblogs.com/wangxu01/articles/11646053.html
https://www.cnblogs.com/lz1996/p/12741489.html
https://www.jianshu.com/p/87e1ca5b84c9