
术语
175B、60B、540B等
这些一般指参数的个数,B是Billion/十亿的意思,175B是1750亿参数,这是ChatGPT大约的参数规模。
Accelerator 加速器
一种微处理器,设计用于加速AI应用。
A class of microprocessor designed to accelerate AI applications.
Agents 代理
可以独立并主动地执行某些任务,无需人类干预的软件,常常使用一套工具,如计算器或网络浏览。
Software that can perform certain tasks independently and proactively without the need for human intervention, often utilizing a suite of tools like calculators or web browsing.
AGI (Artificial General Intelligence) 通用人工智能
虽然并无广泛共识,但微软研究员已经将AGI定义为在任何智力任务上都与人类一样有能力的人工智能。
Though not widely agreed upon, Microsoft researchers have defined AGI as artificial intelligence that is as capable as a human at any intellectual task.
Alignment 对齐
确保AI系统的目标与人类价值观一致的任务。The task of ensuring that the goals of an AI system are in line with human values.
ASI (Artificial Super Intelligence)超级人工智能
Though subject to debate, ASI is commonly defined as artificial intelligence that surpasses the capabilities of the human mind.尽管存在争议,但ASI通常被定义为超越人类思维能力的人工智能。
Attention 注意力(Transformer模型重要组成)
在神经网络的上下文中,注意力机制帮助模型在生成输出时专注于输入的相关部分。
In the context of neural networks, attention mechanisms help the model focus on relevant parts of the input when producing an output.
Back Propagation 反向传播
这是一种在训练神经网络中常用的算法,指的是计算损失函数相对于网络权重的梯度的方法。
An algorithm often used in training neural networks, referring to the method for computing the gradient of the loss function with respect to the weights in the network.
Bias 偏差
AI模型对数据所做的假设。”偏差-方差权衡”是模型对数据的假设与模型的预测随着训练数据的变化而变化的平衡。归纳偏差是机器学习算法对数据底层分布的一组假设。
Assumptions made by an AI model about the data. A “bias variance tradeoff” is the balance that must be achieved between assumptions a model makes about the data and the amount a model’s predictions change, given different training data. Inductive bias is the set of assumptions that a machine learning algorithm makes on the underlying distribution of the data.
Chain of Thought (CoT) 思维链
大模型提示工程中的重要技术,这个词通常用来描述AI模型在达到决策时使用的推理步骤序列。
In AI, this term is often used to describe the sequence of reasoning steps an AI model uses to arrive at a decision.
Chatbot 聊天机器人
一种计算机程序,设计用于通过文本或语音交互模拟人类对话。聊天机器人经常利用自然语言处理技术来理解用户输入并提供相关的响应。
A computer program designed to simulate human conversation through text or voice interactions. Chatbots often utilize natural language processing techniques to understand user input and provide relevant responses.
ChatGPT 不需多解释
由OpenAI开发的基于GPT微调的AI大语言模型应用,可以生成模仿人类的文本,可以完成写文章,写软件程序代码等等多种任务。
A large-scale AI language model developed by OpenAI that generates human-like text.
CLIP (Contrastive Language–Image Pretraining)
OpenAI开发的一种AI模型,它将图像和文本相连接,使其能够理解和生成图像的描述。
An AI model developed by OpenAI that connects images and text, allowing it to understand and generate descriptions of images.
Compute 算力
用于训练或运行AI模型的计算资源(如CPU或GPU时间)。
The computational resources (like CPU or GPU time) used in training or running AI models.
Convolutional Neural Network (CNN)卷积神经网络
一种深度学习模型,通过应用一系列滤波器来处理具有网格状拓扑结构(例如,图像)的数据。这类模型常用于图像识别任务。
A type of deep learning model that processes data with a grid-like topology (e.g., an image) by applying a series of filters. Such models are often used for image recognition tasks.
Data Augmentation:数据增强
通过添加已有数据的略微修改的副本来增加用于训练模型的数据量和多样性的过程。
The process of increasing the amount and diversity of data used for training a model by adding slightly modified copies of existing data.
Data Set 数据集
一组样本的集合。
Deep Learning 深度学习
机器学习的一个子领域,专注于训练具有多层的神经网络,使其能够学习复杂的模式。
A subfield of machine learning that focuses on training neural networks with many layers, enabling learning of complex patterns.
Diffusion 扩散
在AI和机器学习中,扩散是一种生成新数据的技术,它从一块真实数据开始并添加随机噪声。扩散模型是一种生成模型,其中神经网络被训练以预测当随机噪声添加到数据时的反向过程。扩散模型被用来生成与训练数据相似的新样本。
In AI and machine learning, a technique used for generating new data by starting with a piece of real data and adding random noise. A diffusion model is a type of generative model in which a neural network is trained to predict the reverse process when random noise is added to data. Diffusion models are used to generate new samples of data that are similar to the training data.
Double Descent 双下降
机器学习中的一个现象,模型性能随着复杂性的增加而提高,然后变差,然后再次提高。
A phenomenon in machine learning in which model performance improves with increased complexity, then worsens, then improves again.
Embedding 嵌入
数据的新形式的表示,通常是一个向量空间。相似的数据点有更相似的嵌入。
The representation of data in a new form, often a vector space. Similar data points have more similar embeddings.
Emergence/Emergent Behavior (“sharp left turns,” intelligence explosions) 涌现/涌现行为(“急转左”,智慧爆炸)
在AI中,涌现指的是从简单的规则或交互中产生的复杂行为。“急转左”和“智能爆炸”是AI发展突然和剧烈转变的推测性场景,通常与AGI的到来有关。
In AI, emergence refers to complex behavior arising from simple rules or interactions. “Sharp left turns” and “intelligence explosions” are speculative scenarios where AI development takes sudden and drastic shifts, often associated with the arrival of AGI.
End-to-End Learning 端到端学习
一种不需要手工设计特征的机器学习模型。模型只需输入原始数据并从这些输入中学习。
A type of machine learning model that does not require hand-engineered features. The model is simply fed raw data and expected to learn from these inputs.
Expert Systems 专家系统
应用人工智能技术提供特定领域内复杂问题解决方案的应用。
An application of artificial intelligence technologies that provides solutions to complex problems within a specific domain.
Explainable AI (XAI) 可解释的AI
AI的一个子领域,专注于创建提供清晰易懂决策解释的透明模型。
A subfield of AI focused on creating transparent models that provide clear and understandable explanations of their decisions.
Fine-tuning 微调
取一个已经在大数据集上训练过的预训练机器学习模型,并将其调整以适应略有不同的任务或特定领域的过程。在微调过程中,使用较小的、针对特定任务的数据集进一步调整模型的参数,使其能够学习任务特定的模式并提高在新任务上的性能。
The process of taking a pre-trained machine learning model that has already been trained on a large dataset and adapting it for a slightly different task or specific domain. During fine-tuning, the model’s parameters are further adjusted using a smaller, task-specific dataset, allowing it to learn task-specific patterns and improve performance on the new task.
Forward Propagation 前向传播
在神经网络中,前向传播是将输入数据送入网络,并通过每一层(从输入层到隐藏层,最后到输出层)产生输出的过程。网络将权重和偏差应用于输入,并使用激活函数生成最终输出。
In a neural network, forward propagation is the process where input data is fed into the network and passed through each layer (from the input layer to the hidden layers and finally to the output layer) to produce the output. The network applies weights and biases to the inputs and uses activation functions to generate the final output.
Foundation Model 基础模型
在广泛数据上训练的大型AI模型,用于适应特定任务。
Large AI models trained on broad data, meant to be adapted for specific tasks.
General Adversarial Network (GAN) 生成对抗网络
一种用于生成与现有数据相似的新数据的机器学习模型。它使两个神经网络相互对抗:“生成器”创建新数据,“判别器”试图区分该数据与真实数据。
A type of machine learning model used to generate new data similar to some existing data. It pits two neural networks against each other: a “generator,” which creates new data, and a “discriminator” which tries to distinguish that data from real data.
Generative AI 生成式AI
AI的一个分支,专注于创建可以基于现有数据的模式和示例生成新的和原创内容的模型,如图像、音乐或文本。比如ChatGPT,MidJouney。
A branch of AI focused on creating models that can generate new and original content, such as images, music, or text, based on patterns and examples from existing data.
Generalization 泛化
模型泛化是指一些模型可以应用(泛化)到其他场景,通常为采用迁移学习、微调等手段实现泛化。
GPT (Generative Pretrained Transformer) 生成式预训练Transformer模型
由OpenAI开发的AI大语言模型,可以生成类似人类的文本…ChatGPT就是基于这个模型微调完成的产品。
A large-scale AI language model developed by OpenAI that generates human-like text.
GPU (Graphics Processing Unit) 图形处理器
一种专用的微处理器,主要设计用于快速渲染图像以输出到显示器。GPU也非常适合执行训练和运行神经网络所需的计算。
A specialized type of microprocessor primarily designed to quickly render images for output to a display. GPUs are also highly efficient at performing the calculations needed to train and run neural networks.
Gradient Descent 梯度下降
在机器学习中,梯度下降是一种优化方法,它根据损失函数的最大改善方向逐步调整模型的参数。例如,在线性回归中,梯度下降通过反复调整线的斜率和截距以最小化预测误差,帮助找到最佳拟合线。
In machine learning, gradient descent is an optimization method that gradually adjusts a model’s parameters based on the direction of largest improvement in its loss function. In linear regression, for example, gradient descent helps find the best-fit line by repeatedly refining the line’s slope and intercept to minimize prediction errors.
Hallucinate/Hallucination 幻觉
在AI的上下文中,幻觉是指模型生成不基于实际数据或与现实显著不同的内容的现象。
In the context of AI, hallucination refers to the phenomenon in which a model generates content that is not based on actual data or is significantly different from reality.
Hidden Layer 隐藏层
神经网络中的隐藏层指的是不直接连接到输入或输出的人工神经元层。
Layers of artificial neurons in a neural network that are not directly connected to the input or output.
Hyperparameter Tuning 超参数调优
选择机器学习模型的超参数(不从数据中学习的参数)的适当值的过程。
The process of selecting the appropriate values for the hyperparameters (parameters that are not learned from the data) of a machine learning model.
Inference 推理
使用训练过的机器学习模型进行预测的过程。
The process of making predictions with a trained machine learning model.
Instruction Tuning 指令微调
机器学习中的一种技术,其中模型基于数据集中给定的特定指令进行微调。
A technique in machine learning where models are fine-tuned based on specific instructions given in the dataset.
Large Language Model (LLM) 大型语言模型
一种可以生成类人文本并在广泛数据集上训练的AI模型。
A type of AI model that can generate human-like text and is trained on a broad dataset.
Latent Space 潜空间(潜特征空间或嵌入空间)
在机器学习中,这个术语指的是模型(如神经网络)创建的数据的压缩表示。相似的数据点在潜在空间中更接近。
In machine learning, this term refers to the compressed representation of data that a model (like a neural network) creates. Similar data points are closer in latent space.
Loss Function (or Cost Function) 损失函数
机器学习模型在训练期间寻求最小化的函数。它量化模型预测与真实值之间的差距。
A function that a machine learning model seeks to minimize during training. It quantifies how far the model’s predictions are from the true values.
Machine Learning 机器学习
机器学习是一门人工智能的科学,该领域的主要研究对象是人工智能,特别是如何在经验学习中改善具体算法的性能。提供系统自动学习和从经验中改进的能力,无需明确编程。
A type of artificial intelligence that provides systems the ability to automatically learn and improve from experience without being explicitly programmed.
Mixture of Experts 多专家模型/混合专家系统
是在神经网络 (Neural Network, NN) 领域发展起来的一种集成学习(Ensemble Learning) 技术。传统的深度学习模型在训练时,对于每个输入样本,整个网络都会参与计算。随着模型越来越大,训练使用的样本数据越来越多,训练的开销越来越难以承受。而 MoE 可以动态激活部分神经网络,从而实现在不增加计算量的前提下大幅度增加模型参数量。MoE 技术目前是训练万亿参数量级模型的关键技术。
A machine learning technique where several specialized submodels (the “experts”) are trained, and their predictions are combined in a way that depends on the input.
Multimodal 多模态
模态(modal)是事情经历和发生的方式,我们生活在一个由多种模态(Multimodal)信息构成的世界,包括视觉信息、听觉信息、文本信息、嗅觉信息等等,在人工智能领域多模态经常指的是多种模态的信息,包括:文本、图像、视频、音频等。
In AI, this refers to models that can understand and generate information across several types of data, such as text and images.
Natural Language Processing (NLP)自然语言处理
AI的一个子领域,专注于通过自然语言进行计算机和人类之间的交互。NLP的最终目标是阅读、解码、理解,并以有价值的方式理解人类语言。
A subfield of AI focused on the interaction between computers and humans through natural language. The ultimate objective of NLP is to read, decipher, understand, and make sense of human language in a valuable way.
NeRF (Neural Radiance Fields) 神经辐射场
一种计算机视觉技术,用于生成高质量的三维重建模型。使用神经网络从2D图像创建3D场景的方法。它可用于照片级渲染、视图合成等。它利用深度学习技术从多个视角的图像中提取出对象的几何形状和纹理信息,然后使用这些信息生成一个连续的三维辐射场,从而可以在任意角度和距离下呈现出高度逼真的三维模型。
A method for creating a 3D scene from 2D images using a neural network. It can be used for photorealistic rendering, view synthesis, and more.
Neural Network 神经网络
一种受人脑启发的AI模型。它由连接的单元或节点组成,这些节点被称为神经元,它们在各层之间进行组织。神经元接受输入,在其上进行一些计算,并产生输出。
A type of AI model inspired by the human brain. It consists of connected units or nodes—called neurons—that are organized in layers. A neuron takes inputs, does some computation on them, and produces an output.
Objective Function 目标函数
机器学习模型在训练期间寻求最大化或最小化的函数。
A function that a machine learning model seeks to maximize or minimize during training.
Overfitting 过拟合
当函数过于紧密地拟合有限的数据点时会发生的建模错误,导致应用于未见数据时预测性能差。
A modeling error that occurs when a function is too closely fit to a limited set of data points, resulting in poor predictive performance when applied to unseen data.
Parameters 参数
在机器学习中,参数是模型用来进行预测的内部变量。它们在训练过程中从训练数据中学习。例如,在神经网络中,权重和偏差就是参数。
In machine learning, parameters are the internal variables that the model uses to make predictions. They are learned from the training data during the training process. For example, in a neural network, the weights and biases are parameters.
Pre-training 预训练
训练机器学习模型的初始阶段,在该阶段模型从数据中学习通用特征、模式和表示,而不需要具体了解将来会应用到的任务。这个无监督或半监督的学习过程使模型能够发展出对底层数据分布的基本理解,并提取出有意义的特征,这些特征可以在后续的微调中用于特定任务。
The initial phase of training a machine learning model where the model learns general features, patterns, and representations from the data without specific knowledge of the task it will later be applied to. This unsupervised or semi-supervised learning process enables the model to develop a foundational understanding of the underlying data distribution and extract meaningful features that can be leveraged for subsequent fine-tuning on specific tasks.
Prompt 提示词(也称“指令”)
为模型设置任务或查询的初始上下文或指令。
The initial context or instruction that sets the task or query for the model.
Regularization 正则化
在机器学习中,正则化是一种用于防止过拟合的技术,通过向模型的损失函数添加惩罚项来实现。这种惩罚阻止模型过度依赖训练数据中的复杂模式,从而促进更具泛化性和较少倾向于过拟合的模型。
In machine learning, regularization is a technique used to prevent overfitting by adding a penalty term to the model’s loss function. This penalty discourages the model from excessively relying on complex patterns in the training data, promoting more generalizable and less prone-to-overfitting models.
Reinforcement Learning 强化学习
一种机器学习类型,其中一个代理通过在环境中采取行动以最大化某些奖励来学习决策。
A type of machine learning where an agent learns to make decisions by taking actions in an environment to maximize some reward.
RLHF (Reinforcement Learning from Human Feedback) 基于人类反馈的强化学习
一种通过从人类对模型输出给出的反馈中学习来训练AI模型的方法。
A method to train an AI model by learning from feedback given by humans on model outputs.
Singularity 奇点
在AI的语境中,奇点(也称为技术奇点)指的是一个假设的未来时间点,当时技术增长变得无法控制和不可逆转,导致对人类文明的无法预见的变化。
In the context of AI, the singularity (also known as the technological singularity) refers to a hypothetical future point in time when technological growth becomes uncontrollable and irreversible, leading to unforeseeable changes to human civilization.
Supervised Learning 监督学习
监督学习是机器学习的一个分支,是一种数据分析方法,它使用从数据中迭代学习的算法,使计算机无需明确编程就能够发现隐藏的洞见。
A type of machine learning where the model is provided with labeled training data.
Symbolic Artificial Intelligence 符号人工智能
一种利用符号推理来解决问题和表示知识的AI类型。
A type of AI that utilizes symbolic reasoning to solve problems and represent knowledge.
Temperature
从生成模型中抽样包含随机性,因此每次点击“生成”时,相同的提示可能会产生不同的输出。温度是用于调整随机程度的数字。
TensorFlow
由Google开发的开源机器学习平台,用于构建和训练机器学习模型。
An open-source machine learning platform developed by Google that is used to build and train machine learning models.
TPU (Tensor Processing Unit) 张量处理单元
张量处理单元 (TPU) 是 Google 定制开发的专用集成电路 (ASIC),用于加速机器学习工作负载。
A type of microprocessor developed by Google specifically for accelerating machine learning workloads.
Token 文本中的最小单位
Token 可以被理解为文本中的最小单位。在英文中,一个 token 可以是一个单词,也可以是一个标点符号。在中文中,通常以字或词作为 token。ChatGPT 将输入文本拆分成一个个 token,使模型能够对其进行处理和理解。
Top-k & Top-p
选择输出标记的方法是使用语言模型生成文本的一个关键概念。有几种方法(也称为解码策略)用于选择输出token,其中两种主要方法是 top-k 采样和 top-p 采样。
Training Data 训练数据
用于训练机器学习模型的数据集。
The dataset used to train a machine learning model.
Transfer Learning 迁移学习
机器学习中的一种方法,其中预先训练的模型被用于新的问题。
A method in machine learning where a pre-trained model is used on a new problem.
Transformer
用于处理自然语言等向量数据的特定类型的神经网络架构。Transformer以其处理数据中长距离依赖性的能力而闻名,这要归功于一种称为“注意力”的机制,它允许模型在产生输出时权衡不同输入的重要性。
A specific type of neural network architecture used primarily for processing sequential data such as natural language. Transformers are known for their ability to handle long-range dependencies in data, thanks to a mechanism called “attention,” which allows the model to weigh the importance of different inputs when producing an output.
Underfitting 欠拟合
当统计模型或机器学习算法无法充分捕捉数据的底层结构时,统计和机器学习中的建模错误。
A modeling error in statistics and machine learning when a statistical model or machine learning algorithm cannot adequately capture the underlying structure of the data.
Unsupervised Learning 无监督学习
一种机器学习类型,其中模型没有提供带标签的训练数据,而必须自己识别数据中的模式。
A type of machine learning where the model is not provided with labeled training data, and instead must identify patterns in the data on its own.
Validation Data 验证数据
用于机器学习的数据集的一个子集,它与训练和测试数据集是分开的。它被用来调整模型的超参数(即,结构,而不是权重)。
A subset of the dataset used in machine learning that is separate from the training and test datasets. It’s used to tune the hyperparameters (i.e., architecture, not weights) of a model.
XAI (Explainable AI) 可解释AI
专注于创建提供明确且易于理解的决策解释的透明模型的AI子领域。
A subfield of AI focused on creating transparent models that provide clear and understandable explanations of their decisions.
Zero-shot Learning 零样本学习
一种机器学习技术,其中模型在未经微调的情况下,对训练期间未见过的条件进行预测。
A type of machine learning where the model makes predictions for conditions not seen during training, without any fine-tuning.
Prompt Engineering 提示工程
提示工程(Prompt Engineering)是一门较新的学科,关注提示词开发和优化,帮助用户将大语言模型(Large Language Model, LLM)用于各场景和研究领域。掌握了提示工程相关技能将有助于用户更好地了解大型语言模型的能力和局限性。用户可利用提示工程来提升大语言模型处理复杂任务场景的能力,如问答和算术推理能力。开发人员可通过提示工程设计、研发强大的工程技术,实现和大语言模型或其他生态工具的高效接轨。
Prompt engineering is a relatively new discipline for developing and optimizing prompts to efficiently use language models (LMs) for a wide variety of applications and research topics. Prompt engineering skills help to better understand the capabilities and limitations of large language models (LLMs).Researchers use prompt engineering to improve the capacity of LLMs on a wide range of common and complex tasks such as question answering and arithmetic reasoning. Developers use prompt engineering to design robust and effective prompting techniques that interface with LLMs and other tools.
Prompt Engineering 提示工程
在NLP大模型中,基于上下文学习、少样本学习或少样本提示是一种提示工程技术,它允许模型在尝试任务之前处理一些示例。
Few shot Prompting In natural language processing, in-context learning, few-shot learning or few-shot prompting is a prompting technique that allows a model to process examples before attempting a task.
详解AI大模型行业黑话,迅速搞懂提示工程(prompt)、向量工程(embedding)、微调工程(fine-tune)
大家都在讨论大模型,似乎什么都可以与大模型结合,可当初学者也想上手时,却面临一堆令人头大的词汇,什么Prompt、、Embedding、Fine-tuning,看到瞬间头都大了。一堆英文就算了,还不容易查到正确解释,怎么办呢?别担心,本文就用一种有趣的方式让大家认识它们。
首先让我们先了解一下作为人类是如何去使用大模型的。我们可以把大模型当做一个对语言有着出色理解能力的人,我们要做的就是通过文本的输入,让大模型理解我们希望他做什么事情。那么学会向大模型提问,就变成了用好大模型最重要的事情,甚至可以说使用大模型的过程就是向大模型提问的过程。
那么有哪些概念需要我们了解呢?
Prompt
是输入给大模型的文本,用来提示或引导大模型给出符合预期的输出。在上面这个与星火大模型的对话中,我们向大模型提问的文本就是提示词,而大模型在理解了我们的提示词后就在提示词的下面会给出对应的回答。
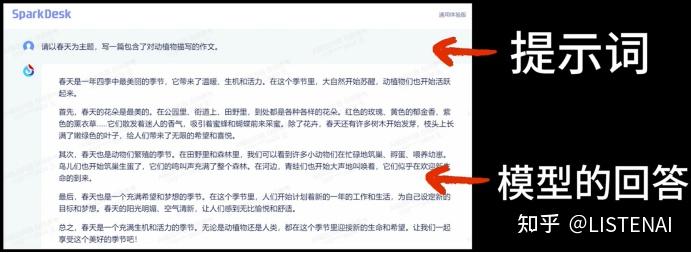
Prompt = 提示词 = 人与大模型交互的媒介
打个比方,假如我们是产品经理,大模型是一名研发工程师的话,那么提示词就是需求,产品经理在提需求的时候,需要在需求里面包含背景说明、需求说明、版本要求、方案建议等信息,只有把需求描述得足够清晰,工程师才能够按照需求输出符合要求的代码,提示词就相当于人向大模型提需求时的需求文档.
Token
我们可以经常在大模型的计费说明中看到Token这个词,Token是大模型处理的最小单元,比如英文单词或者汉字。

Token长度 = 与大模型交互时使用的单词、汉字数
不同的人表达同一件事情时,有的人言简意赅几句话就能把事情说得明明白白,而有的人可能表达能力不好,非常的啰嗦,才能把这件事情说清楚。那么很明显这个啰嗦的人在描述这件事情上消耗的Token就比前面那个人多了很多。
Emdedding
是将段落文本编码成固定维度的向量,便于进行语义相似度的比较。
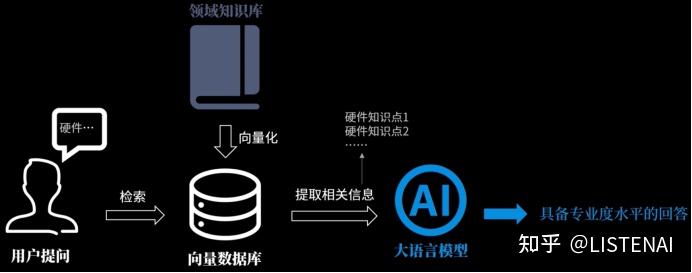
我们可以理解成把知识数据向量化成一个数据库,是为了方便检索,这让用户在提问的时候,我们就可以根据用户的提问内容,在数据库中提取相关度比较高的材料,一起给到大模型,这样大模型就能用这些专业的知识做出更加具备专业水平的回答了。
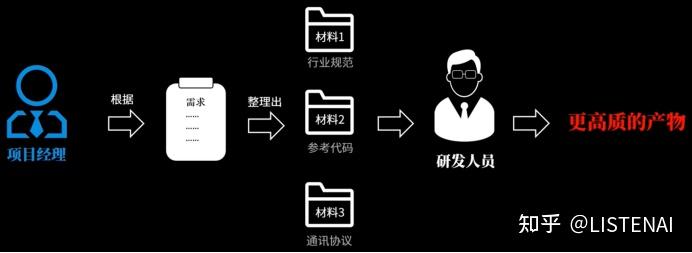
打个比方,Emdedding就像是当一个项目启动时,项目经理把待完成需求所依据的额外相关材料先整理好,提取重点后放在附件中给到研发工程师,便于研发工程师高效的输出符合预期的东西。
Fine-Tune
在已经训练好的模型基础上进一步调整模型的过程吗,是一种使用高质量数据对模型参数进行微调的知识迁移技术,目的是让模型更匹配对特定任务的理解。
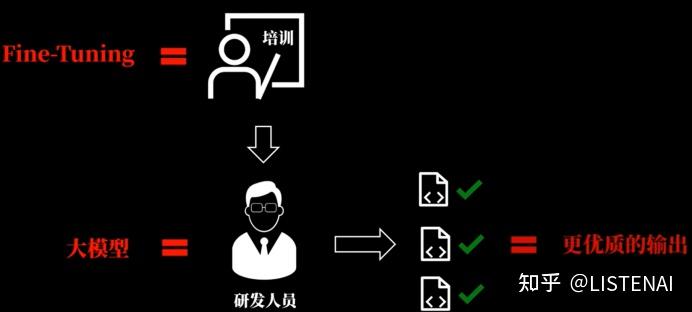
我们可以把大模型类比为公司的研发人员,根据需求生产出对应的产品,而每个研发人员的开发经验都有所不同,输出的代码风格质量也不一样。这就像每个大模型背后使用的训练数据和方法不一样,当面对一样的问题时,做出的回答也会有所差异。那么如何让研发人员输出的代码符合公司的要求呢?答案就是进行培训,由入职导师对研发人员进行代码规范,以及其他需要遵循规则的培训,让他们直接把这些规则记住,这样子他们在做项目开发的时候,就可以直接输出符合规范的产物了。这里的培训类似于大模型的Fine-Tuning,经过Fine-Tuning这个二次训练,大模型更加清楚的知道我们对它输出内容的要求,也就可以输出更加让我们满意的回答了。
把Promp、Token、Emdedding、Fine-Tuning这些大模型词汇串起来,看看用到这些技术的大模型就可以实现下图所示的应用场景。 在下图这个例子中,我们要把一个设备使用手册做成支持大模型问答的应用,这样当我们在使用产品过程中有疑问时,就不需要自己去翻厚厚的说明书了,而是可以直接向大模型提问。
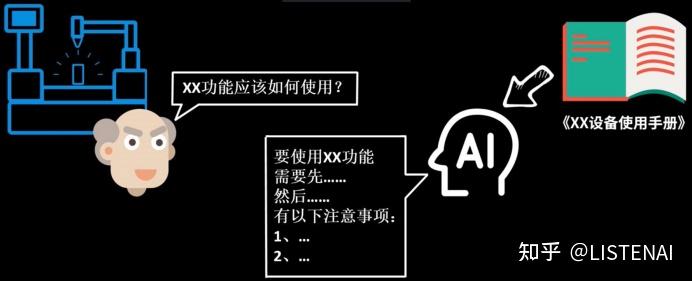
问题来了
如何让大模型学会这本厚厚的说明书,然后来回答我们的问题呢?
首先我们可以通过Emdedding将这本说明书的文本内容向量化为一个数据库,当用户提问的时候,就可以通过提问的内容在这个数据库中检索出相关的内容,然后跟用户的提问一起组合成完整的Prompt给到我们的语言大模型去处理。根据前面文档的讲解,我们也知道提交给大模型的Prompt内容越多,消耗的token也就越多。而刚才把说明书的内容向量化,并支持相关性线索并提取出来作为problem的过程就是Emdedding。当我们把用户跟这个设备相关的问题提交给大模型时,大模型已经可以给出对应的答案了。
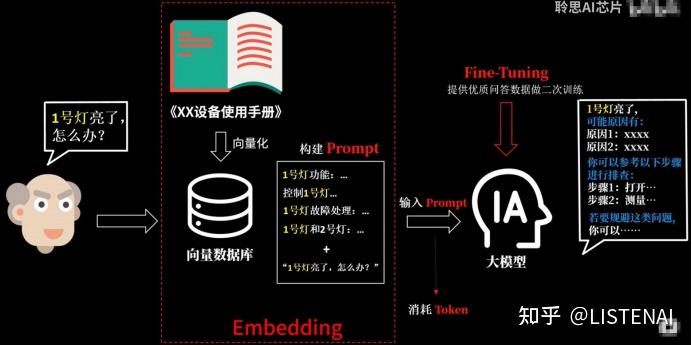
但假如在使用的过程中,我们希望大模型给出的回答可以更加贴合设备问题排查的格式,这时候我们就可以使用微调 的技术,也就是Fine-Tuning通过一些优质的问答数据对大模型进行训练微调,使他的回答更加符合我们的期望。
此外,基于Emdedding加Prompt的方案,一般输入消耗的都可能会很长,导致调用的成本更高,响应时间更长。如果将用户说明书中被提问的高频问题通过Fine-Tuning融入大模型中,可以大幅减少提问需要消耗的Token、加快响应时间,可见这些技术之间都是相互关联相互配合的。
AI大模型的应用实践总结
随着ChatGPT的迅速出圈,加速了大模型时代的变革。对于以Transformer、MOE结构为代表的大模型来说,传统的单机单卡训练模式肯定不能满足上千(万)亿级参数的模型训练,这时候我们就需要解决内存墙和通信墙等一系列问题,在单机多卡或者多机多卡进行模型训练。
AI集群
由于目前只有3台A800 GPU服务器(共24卡),基于目前现有的一些AI框架和大模型,无法充分利用3台服务器。比如:OPT-66B一共有64层Transformer,当使用Alpa进行流水线并行时,通过流水线并行对模型进行切分,要么使用16卡,要么使用8卡,没法直接使用24卡,因此,GPU服务器最好是购买偶数台(如:2台、4台、8台)。
具体的硬件配置如下:
CPUs: 每个节点具有 1TB 内存的 Intel CPU,物理CPU个数为64,每颗CPU核数为16。
GPUs: 24 卡 A800 80GB GPUs ,每个节点 8 个 GPU(3 个节点)。

目前使用Huggingface Transformers和DeepSpeed进行通过数据并行进行训练(pretrain),单卡可以跑三百亿参数(启用ZeRO-2或ZeRO-3),如OPT-30B,具体训练教程参考官方样例。
使用Alpa进行流水线并行和数据并行进行训练(fine tuning)时,使用了3台共24卡(PP:12,DP:2)进行训练OPT-30B,具体训练教程参考官方样例。但是进行模型训练之前需要先进行模型格式转换,将HF格式转换为Alpa格式的模型文件,具体请参考官方代码。如果不想转换,官网也提供了转换好的模型格式,具体请参考文档:Serving OPT-175B, BLOOM-176B and CodeGen-16B using Alpa。

20230703:前几天对H800进行过性能测试,整体上来说,对于模型训练(Huggingface Transformers)和模型推理(FasterTransformer)都有30%左右的速度提升。但是对于H800支持的新数据类型FP8,目前很多开源框架暂不支持,虽然,Nvidia自家一些开源框架支持该数据类型,目前不算太稳定。

AI处理器(加速卡)
目前,主流的AI处理器无疑是NVIDIA的GPU,NVIDIA的GPU产品主要有GeForce、Tesla和Quadro三大系列,虽然,从硬件角度来看,它们都采用同样的架构设计,也都支持用作通用计算(GPGPU),但因为它们分别面向的目标市场以及产品定位的不同,这三个系列的GPU在软硬件的设计和支持上都存在许多差异。其中,GeForce为消费级显卡,而Tesla和Quadro归类为专业级显卡。GeForce主要应用于游戏娱乐领域,而Quadro主要用于专业可视化设计和创作,Tesla更偏重于深度学习、人工智能和高性能计算。
Tesla:A100(A800)、H100(H800)、A30、A40、V100、P100…
GeForce:RTX 3090、RTX 4090 …
Quadro:RTX 6000、RTX 8000 …
其中,A800/H800是针对中国特供版(低配版),相对于A100/H100,主要区别:
A100的Nvlink最大总网络带宽为600GB/s,而A800的Nvlink最大总网络带宽为400GB/s。
H100的Nvlink最大总网络带宽为900GB/s,而A800的Nvlink最大总网络带宽为400GB/s。
其他的一些国外AI处理器(加速卡):
AMD:GPU MI300X
Intel:Xeon Phi
Google:TPU
国产AI处理器(加速卡):
华为:昇腾910(用于训练和推理),昇腾310(用于推理)。采用自家设计的达芬奇架构。
海光DCU:8100系列(深算一号),以GPGPU架构为基础。
寒武纪:思元370、思元590。
百度:昆仑芯,采用的是其自研XPU架构。
阿里:含光800。
大模型算法
模型结构:
目前主流的大模型都是Transformer、MOE结构为基础进行构建,如果说Transformer结构使得模型突破到上亿参数量,MoE 稀疏混合专家结构使模型参数量产生进一步突破,达到数万亿规模。
大模型算法:
下图详细展示了AI大模型的发展历程:
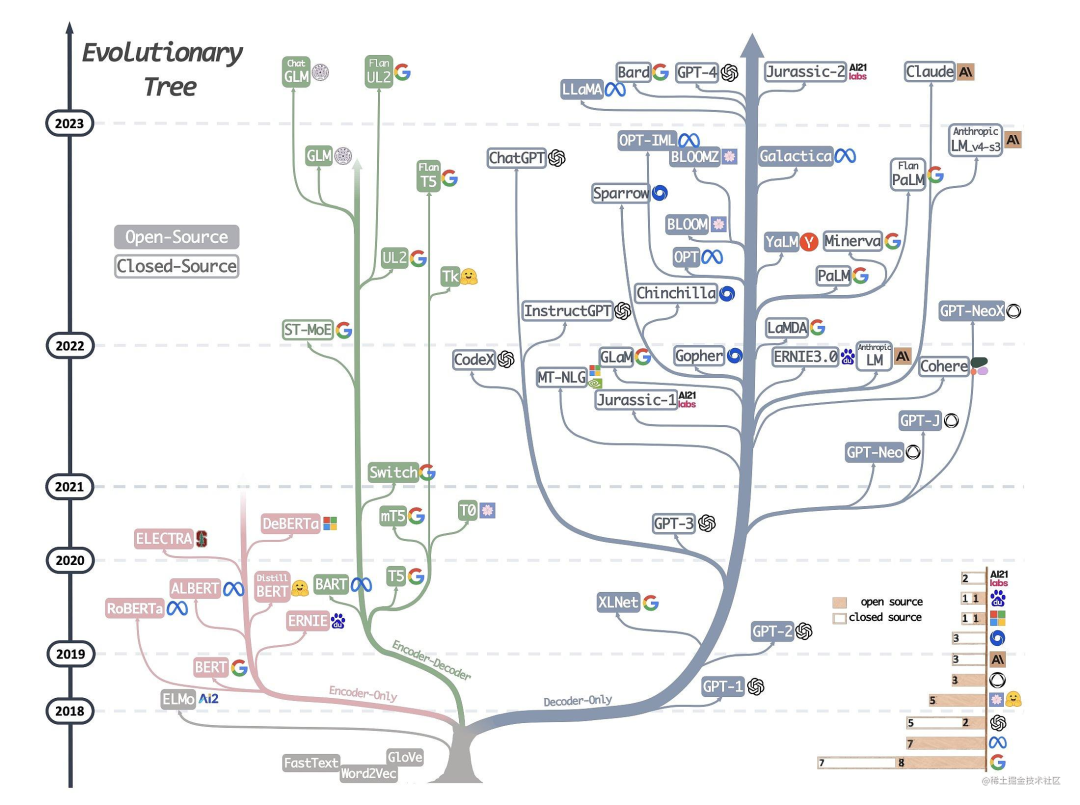
可以说,Transformer 开创了继 MLP 、CNN和 RNN之后的第四大类模型。而基于Transformer结构的模型又可以分为Encoder-only、Decoder-only、Encoder-Decoder这三类。
仅编码器架构(Encoder-only):自编码模型(破坏一个句子,然后让模型去预测或填补),更擅长理解类的任务,例如:文本分类、实体识别、关键信息抽取等。典型代表有:Bert、RoBERTa等。
仅解码器架构(Decoder-only):自回归模型(将解码器自己当前步的输出加入下一步的输入,解码器融合所有已经输入的向量来输出下一个向量,所以越往后的输出考虑了更多输入),更擅长生成类的任务,例如:文本生成。典型代表有:GPT系列、LLaMA、OPT、Bloom等。
编码器-解码器架构(Encoder-Decoder):序列到序列模型(编码器的输出作为解码器的输入),主要用于基于条件的生成任务,例如:翻译,概要等。典型代表有:T5、BART、GLM等。
大语言模型
目前业界可以下载到的一些大语言模型:
ChatGLM-6B / ChatGLM2-6B :清华开源的中英双语的对话语言模型。目前,第二代ChatGLM在官网允许的情况下可以进行商用。
GLM-10B/130B :双语(中文和英文)双向稠密模型。
OPT-2.7B/13B/30B/66B :Meta开源的预训练语言模型。
LLaMA-7B/13B/30B/65B :Meta开源的基础大语言模型。
Alpaca(LLaMA-7B):斯坦福提出的一个强大的可复现的指令跟随模型,种子任务都是英语,收集的数据也都是英文,因此训练出来的模型未对中文优化。
BELLE(BLOOMZ-7B/LLaMA-7B/LLaMA-13B):本项目基于 Stanford Alpaca,针对中文做了优化,模型调优仅使用由ChatGPT生产的数据(不包含任何其他数据)。
Bloom-7B/13B/176B:可以处理46 种语言,包括法语、汉语、越南语、印度尼西亚语、加泰罗尼亚语、13 种印度语言(如印地语)和 20 种非洲语言。其中,Bloomz系列模型是基于 xP3 数据集微调。推荐用于英语的提示(prompting);Bloomz-mt系列模型是基于 xP3mt 数据集微调。推荐用于非英语的提示(prompting)。
Vicuna(7B/13B):由UC Berkeley、CMU、Stanford和 UC San Diego的研究人员创建的 Vicuna-13B,通过在 ShareGPT 收集的用户共享对话数据中微调 LLaMA 获得。其中,使用 GPT-4 进行评估,发现 Vicuna-13B 的性能在超过90%的情况下实现了与ChatGPT和Bard相匹敌的能力;同时,在 90% 情况下都优于 LLaMA 和 Alpaca 等其他模型。而训练 Vicuna-13B 的费用约为 300 美元。不仅如此,它还提供了一个用于训练、服务和评估基于大语言模型的聊天机器人的开放平台:FastChat。
Baize:白泽是在LLaMA上训练的。目前包括四种英语模型:白泽-7B、13B 、 30B(通用对话模型)以及一个垂直领域的白泽-医疗模型,供研究 / 非商业用途使用,并计划在未来发布中文的白泽模型。白泽的数据处理、训练模型、Demo 等全部代码已经开源。
LLMZoo:来自香港中文大学和深圳市大数据研究院团队推出的一系列大模型,如:Phoenix(凤凰) 和 Chimera等。
MOSS:由复旦 NLP 团队推出的 MOSS 大语言模型。
baichuan-7B:由百川智能推出的大模型,可进行商用。
CPM-Bee:百亿参数的开源中英文双语基座大模型,可进行商用。
20230325(当时官方还未开源训练代码,目前直接基于官方的训练代码即可):
前两天测试了BELLE,对中文的效果感觉还不错。具体的模型训练(预训练)方法可参考Hugingface Transformers的样例,SFT(指令精调)方法可参考Alpaca的训练代码。
从上面可以看到,开源的大语言模型主要有三大类:GLM衍生的大模型(wenda、ChatSQL等)、LLaMA衍生的大模型(Alpaca、Vicuna、BELLE、Phoenix、Chimera等)、Bloom衍生的大模型(Bloomz、BELLE、Phoenix等)。
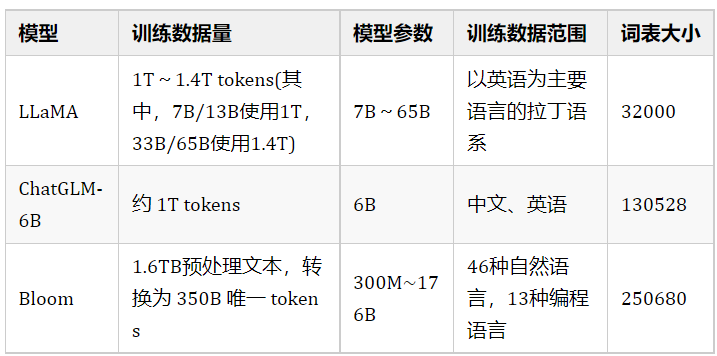
从表格中可以看到,对于像ChatGLM-6B、LLaMA、Bloom这类大模型,要保证基座模型有比较好的效果,至少需要保证上千亿、万亿级的Token量。
目前来看,LLaMA无疑是其中最闪亮的星。但是国内关于LLaMA比较大的一个争论就是LLaMA是以英语为主要语言的拉丁语系上进行训练的,LLaMA词表中的中文token比较少(只有几百个),需不需要扩充词表?如果不扩充词表,中文效果会不会比较差?
如果不扩充词表,对于中文效果怎么样?根据Vicuna官方的报告,经过Instruction Turing的Vicuna-13B已经有非常好的中文能力。
LLaMA需不需要扩充词表?根据Chinese-LLaMA-Alpaca和BELLE的报告,扩充中文词表,可以提升中文编解码效率以及模型的性能。但是扩词表,相当于从头初始化开始训练这些参数。如果想达到比较好的性能,需要比较大的算力和数据量。同时,Chinese-LLaMA-Alpaca也指出在进行第一阶段预训练(冻结transformer参数,仅训练embedding,在尽量不干扰原模型的情况下适配新增的中文词向量)时,模型收敛速度较慢。如果不是有特别充裕的时间和计算资源,建议跳过该阶段。因此,虽然扩词表看起来很诱人,但是实际操作起来,还是很有难度的。
下面是BELLE针对是否扩充词表,数据质量、数据语言分布、数据规模对于模型性能的对比:
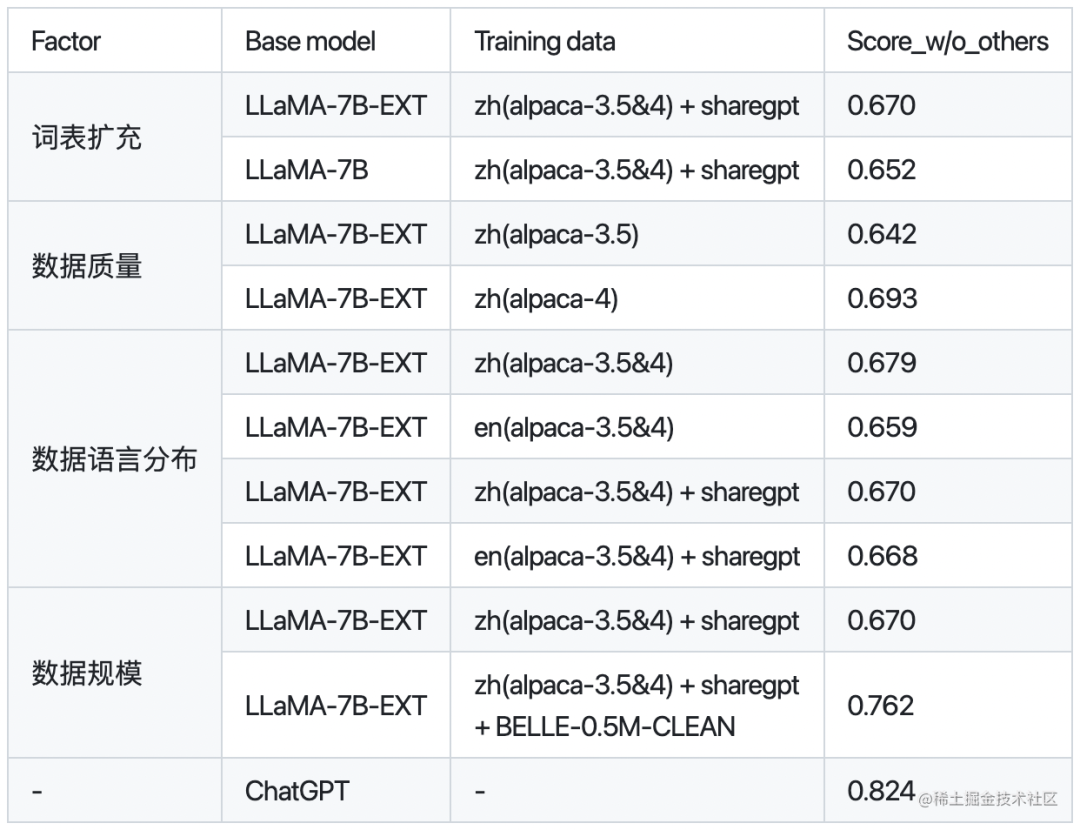
其中,BELLE-0.5M-CLEAN是从230万指令数据中清洗得到0.5M数据(包含单轮和多轮对话数据)。LLaMA-7B-EXT是针对LLaMA做了中文词表扩充的预训练模型。
下面是Chinese-LLaMA-Alpaca针对中文Alpaca-13B、中文Alpaca-Plus-7B、中文Alpaca-Plus-13B的效果对比:
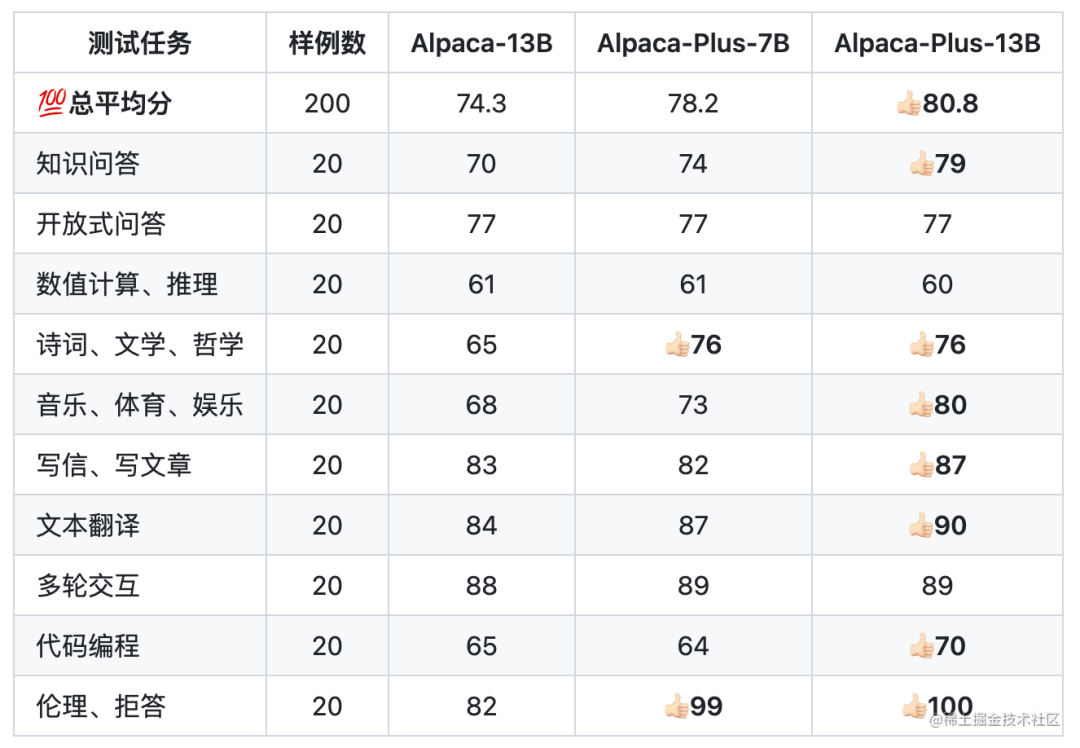
其中,Plus系列Alpaca是在原版LLaMA的基础上扩充了中文词表,使用了120G中文通用纯文本数据进行二次预训练。
因此,如果既想要中文词表,又没有很大的算力,那建议直接使用ChatGLM-6B或者使用BELLE和Chinese-LLaMA-Alpaca进行中文词表扩充后训练好的模型作为Base模型。
多模态大模型
目前业界可以下载到的一些多模态大模型:
MiniGPT-4:沙特阿拉伯阿卜杜拉国王科技大学的研究团队开源。
LLaVA:由威斯康星大学麦迪逊分校,微软研究院和哥伦比亚大学共同出品。
VisualGLM-6B:开源的,支持图像、中文和英文的多模态对话语言模型,语言模型基于 ChatGLM-6B,具有 62 亿参数;图像部分通过训练 BLIP2-Qformer 构建起视觉模型与语言模型的桥梁,整体模型共78亿参数。
VisCPM:于CPM基础模型的中英双语多模态大模型。
领域大模型
金融领域大模型
轩辕:在BLOOM-176B的基础上针对中文通用领域和金融领域进行了针对性的预训练与微调。
Cornucopia(聚宝盆):开源了经过中文金融知识指令精调/指令微调(Instruct-tuning) 的LLaMA-7B模型。通过中文金融公开数据+爬取的金融数据构建指令数据集,并在此基础上对LLaMA进行了指令微调,提高了 LLaMA 在金融领域的问答效果。基于相同的数据,后期还会利用GPT3.5 API构建高质量的数据集,另在中文知识图谱-金融上进一步扩充高质量的指令数据集。
BBT-FinCUGE-Applications:开源了中文金融领域开源语料库BBT-FinCorpus,中文金融领域知识增强型预训练语言模型BBT-FinT5及中文金融领域自然语言处理评测基准CFLEB。
法律领域大模型
ChatLaw:由北京大学开源的大模型,主要有13B、33B。
LexiLaw:LexiLaw 是一个经过微调的中文法律大模型,它基于 ChatGLM-6B 架构,通过在法律领域的数据集上进行微调,使其在提供法律咨询和支持方面具备更高的性能和专业性。
LaWGPT:该系列模型在通用中文基座模型(如 Chinese-LLaMA、ChatGLM 等)的基础上扩充法律领域专有词表、大规模中文法律语料预训练,增强了大模型在法律领域的基础语义理解能力。在此基础上,构造法律领域对话问答数据集、中国司法考试数据集进行指令精调,提升了模型对法律内容的理解和执行能力。
Lawyer LLaMA:开源了一系列法律领域的指令微调数据和基于LLaMA训练的中文法律大模型的参数。Lawyer LLaMA 首先在大规模法律语料上进行了continual pretraining。在此基础上,借助ChatGPT收集了一批对中国国家统一法律职业资格考试客观题(以下简称法考)的分析和对法律咨询的回答,利用收集到的数据对模型进行指令微调,让模型习得将法律知识应用到具体场景中的能力。
医疗领域大模型
DoctorGLM:基于 ChatGLM-6B的中文问诊模型,通过中文医疗对话数据集进行微调,实现了包括lora、p-tuningv2等微调及部署。
BenTsao:源了经过中文医学指令精调/指令微调(Instruct-tuning) 的LLaMA-7B模型。通过医学知识图谱和GPT3.5 API构建了中文医学指令数据集,并在此基础上对LLaMA进行了指令微调,提高了LLaMA在医疗领域的问答效果。
BianQue:一个经过指令与多轮问询对话联合微调的医疗对话大模型,基于ClueAI/ChatYuan-large-v2作为底座,使用中文医疗问答指令与多轮问询对话混合数据集进行微调。
HuatuoGPT:开源了经过中文医学指令精调/指令微调(Instruct-tuning)的一个GPT-like模型。
Med-ChatGLM:基于中文医学知识的ChatGLM模型微调,微调数据与BenTsao相同。
QiZhenGPT:该项目利用启真医学知识库构建的中文医学指令数据集,并基于此在LLaMA-7B模型上进行指令精调,大幅提高了模型在中文医疗场景下效果,首先针对药品知识问答发布了评测数据集,后续计划优化疾病、手术、检验等方面的问答效果,并针对医患问答、病历自动生成等应用展开拓展。
XrayGLM:该项目为促进中文领域医学多模态大模型的研究发展,发布了XrayGLM数据集及模型,其在医学影像诊断和多轮交互对话上显示出了非凡的潜力。
MedicalGPT:训练医疗大模型,实现包括二次预训练、有监督微调、奖励建模、强化学习训练。发布中文医疗LoRA模型shibing624/ziya-llama-13b-medical-lora,基于
Ziya-LLaMA-13B-v1模型,SFT微调了一版医疗模型,医疗问答效果有提升,发布微调后的LoRA权重。
教育领域大模型
桃李(Taoli):一个在国际中文教育领域数据上进行了额外训练的模型。项目基于目前国际中文教育领域流通的500余册国际中文教育教材与教辅书、汉语水平考试试题以及汉语学习者词典等,构建了国际中文教育资源库,构造了共计 88000 条的高质量国际中文教育问答数据集,并利用收集到的数据对模型进行指令微调,让模型习得将知识应用到具体场景中的能力。
EduChat:该项目华东师范大学计算机科学与技术学院的EduNLP团队研发,主要研究以预训练大模型为基底的教育对话大模型相关技术,融合多样化的教育垂直领域数据,辅以指令微调、价值观对齐等方法,提供教育场景下自动出题、作业批改、情感支持、课程辅导、高考咨询等丰富功能,服务于广大老师、学生和家长群体,助力实现因材施教、公平公正、富有温度的智能教育。
数学领域大模型
chatglm-maths:基于chatglm-6b微调/LORA/PPO/推理的数学题解题大模型, 样本为自动生成的整数/小数加减乘除运算, 可gpu/cpu部署,开源了训练数据集等。
RLHF(人工反馈强化学习)
根据 OpenAI 之前做的一些实验,可以看到使用了 PPO(近端策略优化)算法的 RLHF 模型整体上都更好一些。当把结果提供给人类时,相比于 SFT 模型和通过 prompt 化身为助理的基础模型,人类也基本更喜欢来自 RLHF 模型的 token。
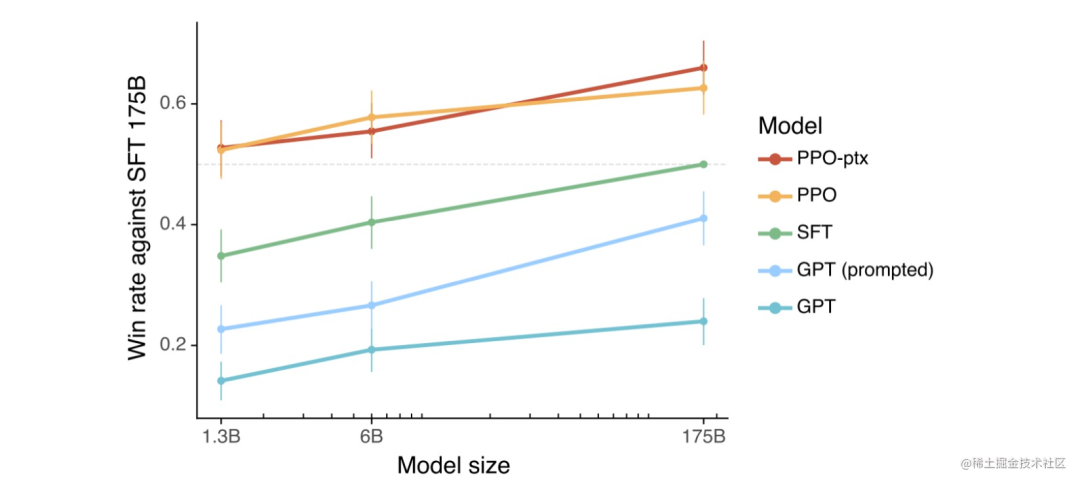
那 RLHF 为什么能让模型更好呢?目前 AI 研究界还没有找到一个得到大家认可的理论,一种可能与比较和生成的计算难度之间的不对称性有关。
举个例子说明一下:假设我们要让一个模型写一首关于回形针的俳句。如果你是一位正努力创建训练数据的合同工,正在为 SFT 模型收集数据。那么你该怎样写出一首关于回形针的好俳句呢?而你可能并不是一位优秀的俳句诗人。但是,如果给你几首俳句,你却有能力辨别它们中哪首更好一些。也就是说,比起创建一个好样本,判断哪个样本更好是简单得多的任务。因此,这种不对称性可能使得比较是一种更好的方法,能更好地利用人类的判断来创造出好一些的模型。
但目前来看,RLHF 并不总是会为基石模型带来提升。在某些情况下,RLHF 模型会失去一些熵,也就是说它们会输出更加单调、变化更少的结果。而基础模型的熵更高,可以输出更加多样化的结果。
RLHF开源工具
下面是目前开源的一些RLHF工具:
DeepSpeed Chat:基于Opt系列模型进行示例。
ColossalChat:基于LLaMA系列模型进行示例。
分布式并行及显存优化技术
并行技术:
数据并行(如:PyTorch DDP)
模型/张量并行(如:Megatron-LM(1D)、Colossal-AI(2D、2.5D、3D))
流水线并行(如:GPipe、PipeDream、PipeDream-2BW、PipeDream Flush(1F1B))
多维混合并行(如:3D并行(数据并行、模型并行、流水线并行))
自动并行(如:Alpa(自动算子内/算子间并行))
优化器相关的并行(如:ZeRO(零冗余优化器,在执行的逻辑上是数据并行,但可以达到模型并行的显存优化效果)、PyTorch FSDP)
显存优化技术:
重计算(Recomputation):Activation checkpointing(Gradient checkpointing),本质上是一种用时间换空间的策略。
卸载(Offload)技术:一种用通信换显存的方法,简单来说就是让模型参数、激活值等在CPU内存和GPU显存之间左右横跳。如:ZeRO-Offload、ZeRO-Infinity等。
混合精度(BF16/FP16):降低训练显存的消耗,还能将训练速度提升2-4倍。
BF16 计算时可避免计算溢出,出现Inf case。
FP16 在输入数据超过65506 时,计算结果溢出,出现Inf case。
分布式训练框架
如何选择一款分布式训练框架?
训练成本:不同的训练工具,训练同样的大模型,成本是不一样的。对于大模型,训练一次动辄上百万/千万美元的费用。合适的成本始终是正确的选择。
训练类型:是否支持数据并行、张量并行、流水线并行、多维混合并行、自动并行等
效率:将普通模型训练代码变为分布式训练所需编写代码的行数,我们希望越少越好。
灵活性:你选择的框架是否可以跨不同平台使用?
常见的分布式训练框架:
第一类:深度学习框架自带的分布式训练功能。如:TensorFlow、PyTorch、MindSpore、Oneflow、PaddlePaddle等。
第二类:基于现有的深度学习框架(如:PyTorch、Flax)进行扩展和优化,从而进行分布式训练。如:Megatron-LM(张量并行)、DeepSpeed(Zero-DP)、Colossal-AI(高维模型并行,如2D、2.5D、3D)、Alpa(自动并行)等
目前训练超大规模语言模型主要有两条技术路线:
TPU + XLA + TensorFlow/JAX :由Google主导,由于TPU和自家云平台GCP深度绑定。
GPU + PyTorch + Megatron-LM + DeepSpeed :由NVIDIA、Meta、MicroSoft大厂加持,社区氛围活跃,也更受到大家欢迎。
对于国内来说,华为昇腾在打造 AI 全栈软硬件平台(昇腾NPU+CANN+MindSpore+MindFormers)。不过目前整个生态相对前两者,还差很远。