
数据仓
ETL工具
工具对比
【国外】
1、datastage (收费)
点评:最专业的ETL工具, 2005年被IBM收购,目前发展到11.7版本。在数据集成的基础上,增加了数据质量分析、数据血缘分析、业务元数据管理等内容。技术支持也比较少,使用难度较大,尤其不菲的价格,导致国内用户较少。
2、informatica (收费)
点评:informatica创立于1993年,专业程度与Datastage旗鼓相当,有4个不同版本,即:标准版,实时版,高级版,云计算版。按用户许可收费,价格比Datastage便宜点。不具有数据质量功能,需要以编程方式进行处理。,没有任何Web集成功能。Informatica与datastage一样需要更高的学习成本。
3、ODI (收费)
点评:oracle数据库厂商提供的工具,有局限性,与oracle数据库耦合太深。ODI属于ELT架构,将数据传输到目标数据后,再目标数据库进行数据清洗转换处理,如果流程过多会对目标数据库有一定压力。对Web集成功能比较弱,运行监控能力比较差,获取技术支持比较困难。
4、kettle(免费)
点评:业界最有名的开源ETL工具。开源当然就免费,免费的有些东西使用就不是很方便。社区版缺乏项目管理、流程管理、运行监控功能,商业版有提供,价格比较高。适合用于少量流程或作为ETL的研究学习。
【国内】
- Datax (免费)
点评:产品化程度还有一定距离。由于没有可视化开发界面,需要编写Java代码。数据清洗转换的能力比较弱,但在大数据传输能力比较好。 - Restcloud(免费)
点评:国产比较好的ETL工具之一,采用B/S架构,可视化化开发,在数据传输与处理的能力与kettle相当,学习成本较低。与kettle比较,增加项目管理、流程管理、质量监测等功能。由于推出时间较短,技术支持目前只能通过社区获取。
其实还有其他比较优秀的,因为公司的流量不大,就选用开源的kettle。
kettle使用
kettle纯java编写,可以在Window、Linux、Unix上运行,绿色无需安装,数据抽取高效稳定。
Kettle工程存储方式:
1、以XML形式存储
2、以资源库方式存储(数据库资源库和文件资源库)
Kettle的两种设计: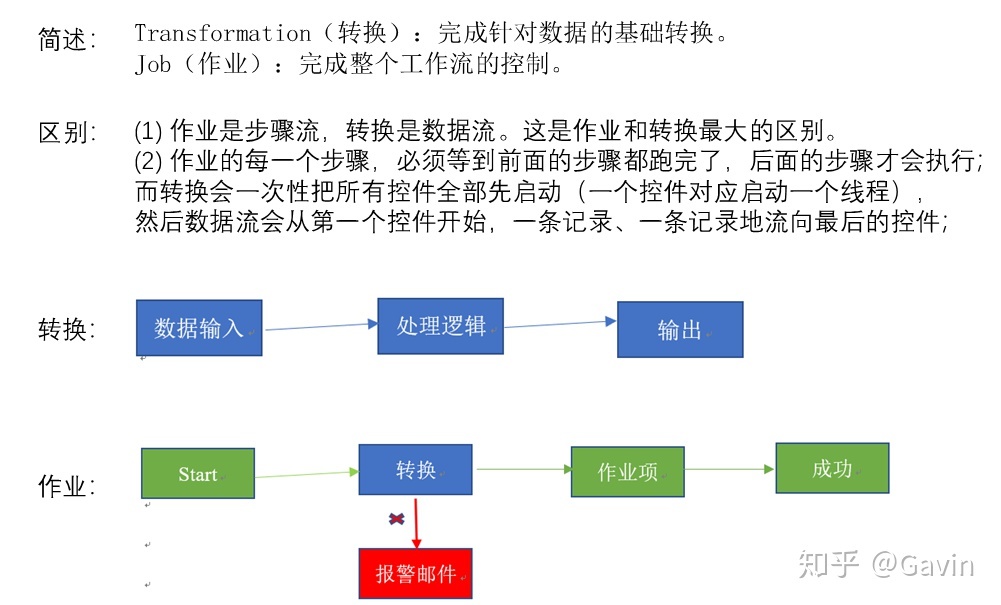
Kettle的组成:
任务保存:
数据库资源需要连接数据库,这里已经用docker创建了kettle相关的数据库,然后使用kettle创建数据库资源库。需要注意的是,创建数据库资源库后,会在C:\USER\XXX.KETTLE目录下生成一个resources.xml的文件,该文件记录了数据库连接的信息,如果用linux版本的任务调度工具,需要把该文件拷贝到相应目录才行
任务调度工具
1、kettle-web
2、taskctl
官网:http://www.taskctl.com/
基础版就已经够用,2022官方新版本8.0,官方建议使用web平台,根据官方教程搭建服务器和客户端,搭建好后使用taskctl的kettle插件来执行kettle任务。
安装教程:
http://www.taskctl.com/forum/detail_124.html
查看配置文件说明:su - kettleiconv -f gbk -t utf-8 $TASKCTLDIR/src/plugin/ktrjob/shell/cprunktrjob.sh
其中有说明kettle的ktr和kjb是如何定义的,通过读取xml标签来获取参数,例如ktr作业:
1 | (三) 作业定义举例: |
拷贝windows版本上的resources.xml文件到/home/kettle/.kettle目录(插件默认读取该文件的数据库连接信息)
登陆taskctl网页,进入admin模块,点击作业类型,可以见到ktrjob和kjbjob的插件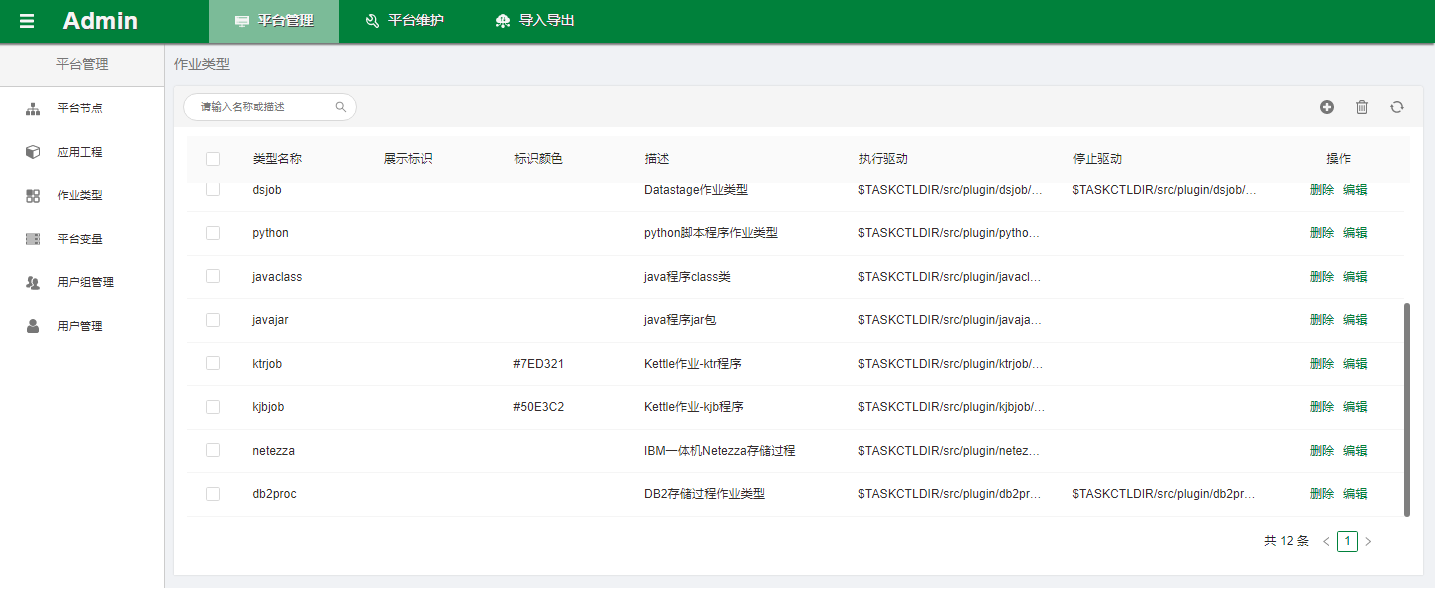
选择designer模块,添加作业资源,点击设计资源,选择作业资源: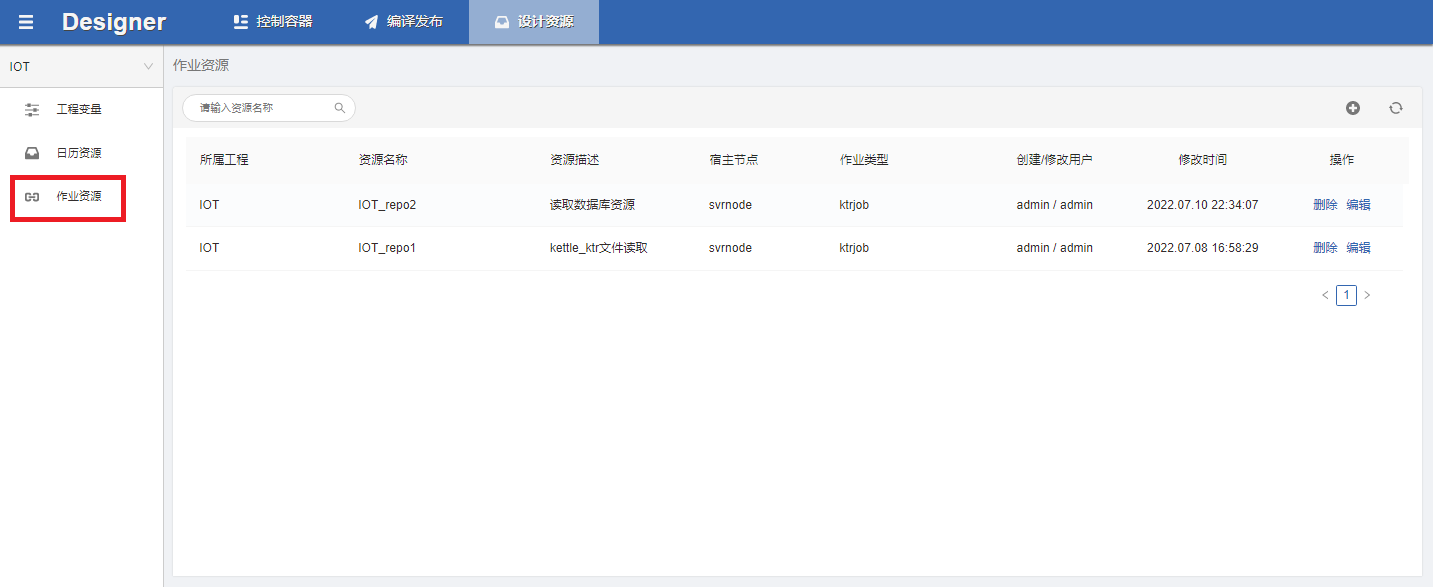
点击加号添加作业资源,这里我设置了两种资源,一种是直接读取本地目录的文件,另一种是读取kettle的数据库资源(预先在kettle的windows环境里面创建好了)
直接读取文件设置
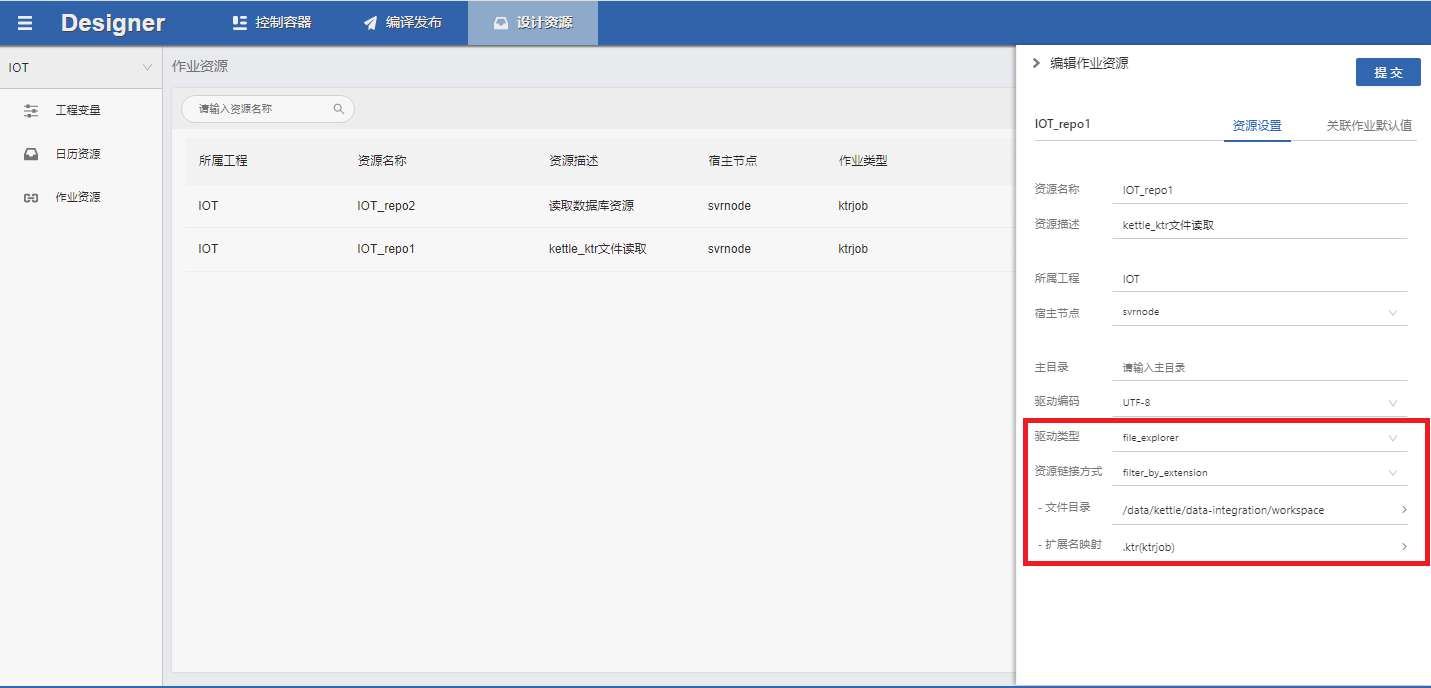
驱动类型选择 file_explorer
资源链接方式选择filter_by_extension
文件目录填作业文件的路径,扩展名是转换作业的填.ktr(ktrjob)是作业的填.kjb(kjbjob)
关联作业类型可以填写作业类型的环境参数,这里只需要填kettle软件的路径就行。
回到控制容器,选择右上角的作业设计,左侧可以选择刚刚建立的作业资源,点击查询,获取到文件名,直接拖到加号创建作业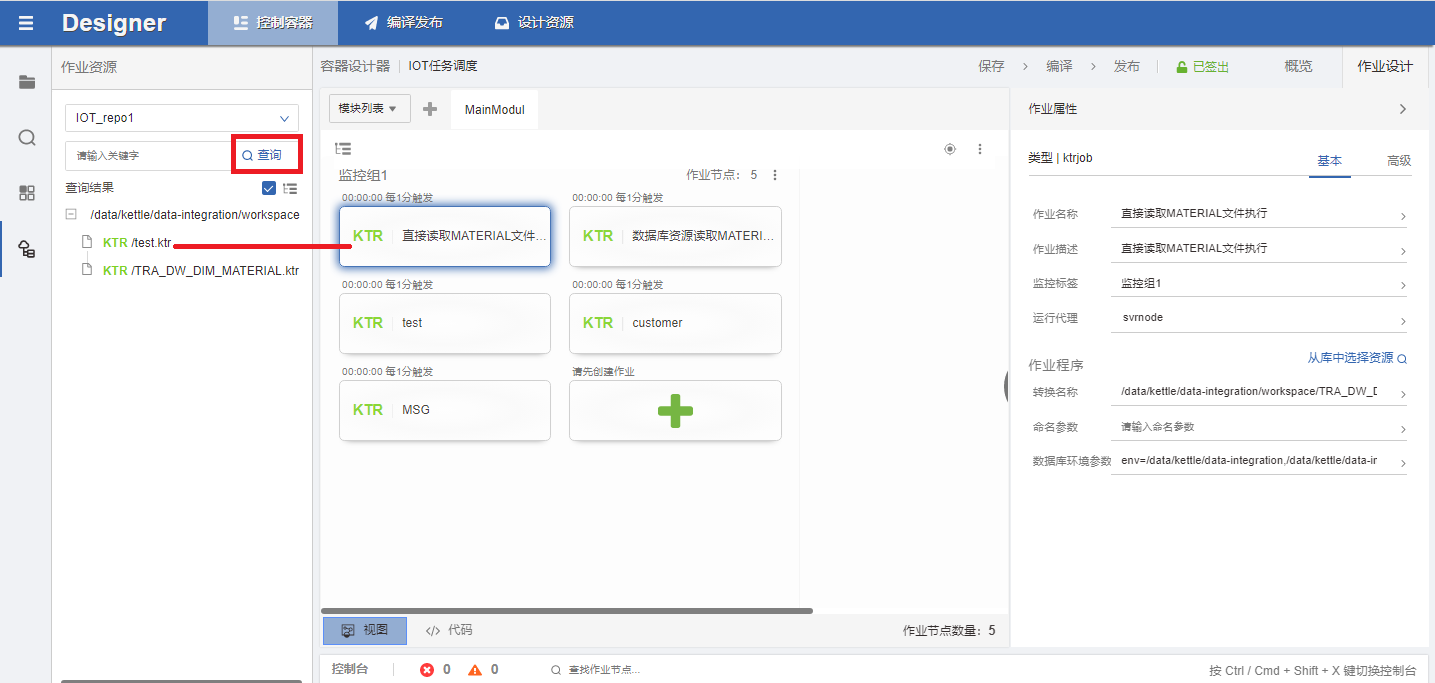
选取运行代理和执行时间计划后提交保存,然后编译发布,就可以到监控模块见到该作业,这里可以先点作业进行调试,调试成功后再点发布,就可以到monitor模块进行作业调度
可以通过代码标签切换查看代码
1 | <!--************************************************************* |
从插件配置文件说明:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
#------------------------------------------------------------------------------
# (一) 功能: 在CTL服务或代理用户执行kettle转换
#
# (二) 参数: 在TASKCTL所有插件中,具有以下统一的参数接口
# 1. tccid 【无用】容器(流程或定时器)ID
# 2. jobid 【无用】作业ID
# 3. progname 【有用】程序名称。程序名对应作业类型的progname属性
# 4. para 【有用】参数信息。参数信息对应作业类型的para属性
# 5. exppara 【有用】环境参数信息。环境参数信息对作业类型的exppara属性
# 6. hostuser 【无用】远程主机用户链接信息。远程主机用户链接信息对应作业类型的hostuser属性
#
# 参数说明:
# (1) progname: 一般为文件系统(.ktr)或资源库的完整路径及名称
#
# (2) para : 一般为kettle作业的命名参数或变量
#
# (3) exppara : 一般为kettle的pan.sh文件所在位置。例如:/home/pdi-ce/data-integration,若需要调用资源库,则需要增加rep(资源库名称),user(资源库用户),pass(资源库密码)
插件会读取:
读取数据库资源库
作业资源库配置实例: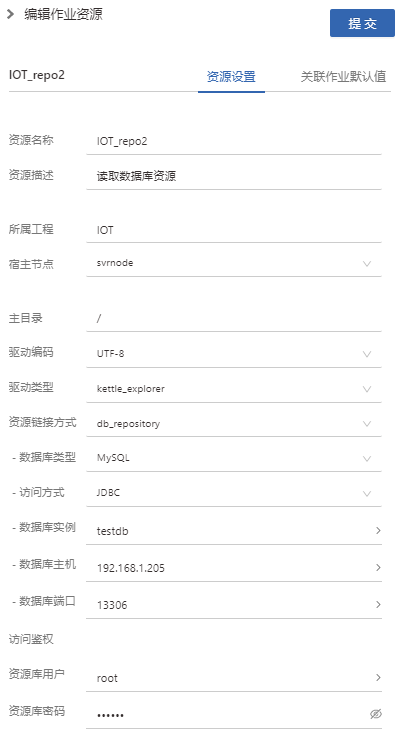
驱动类型选择kttle_explorer
资源链接方式选择db_repository
其他填写数据库连接的信息,同样需要添加管理作业类型,添加ktr,参数为:env=/data/kettle/data-integration,rep=test,user=admin,pass=admin
按照上面添加读取文件一样添加作业即可。
代码:
1 | <ktrjob> |
这里多了rep参数,插件通过这个参数来识别读取类型是否为资源库。然后读取数据库资源的时候,会调用/home/kettle/.kettle目录密码的resources.xml文件的数据库连接参数来连接数据库资源文件。我之前执行任务的时候怎么都报错,说该作业文件不是一个文件,后来才明白,在网页添加的数据库连接参数是插件来获取资源信息,而执行任务的时候是kettle软件pan.sh来读取数据库资源,所以如果没有该数据库连接资源文件,则会执行错误。
任务调度
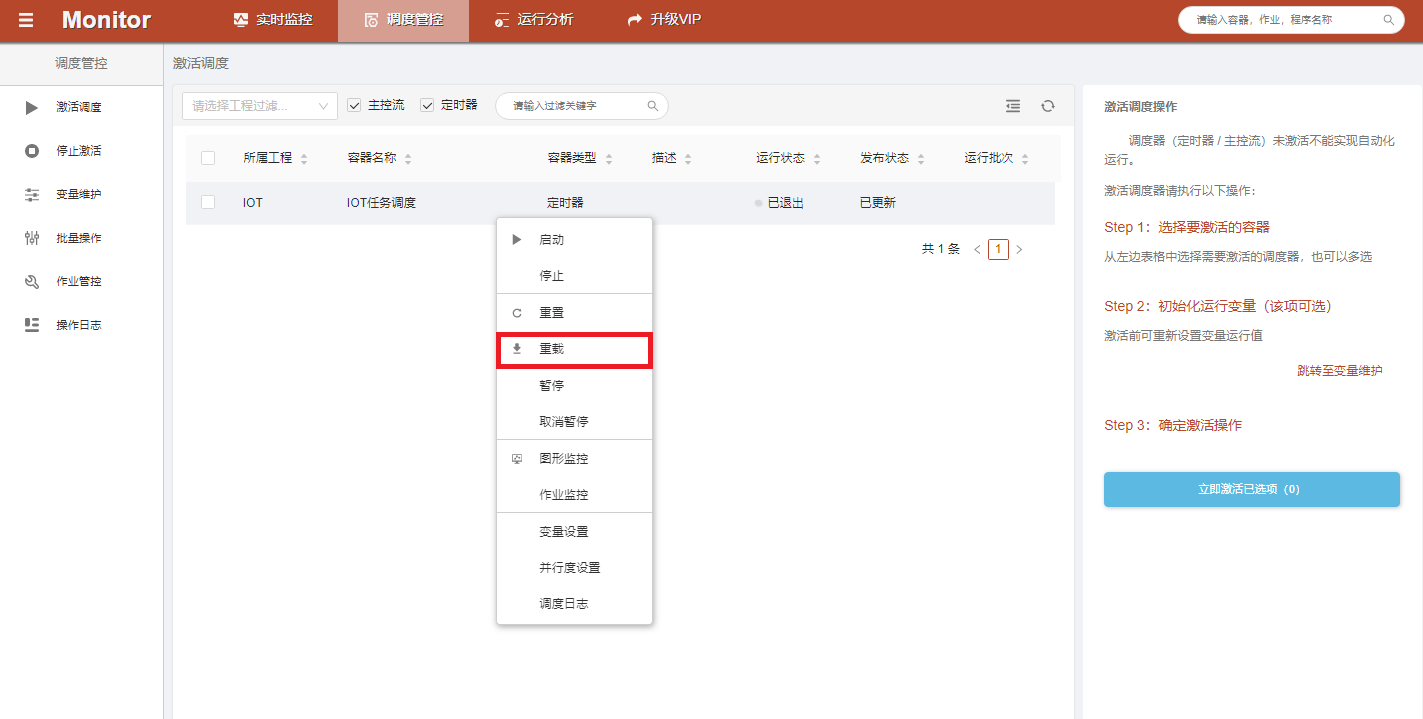
在designer模块任务发布后,就可以在调度监控看到,如果修改了作业,重新发布后,需要在实时监控退出的状态下重载,以获取最新的任务信息。
实践
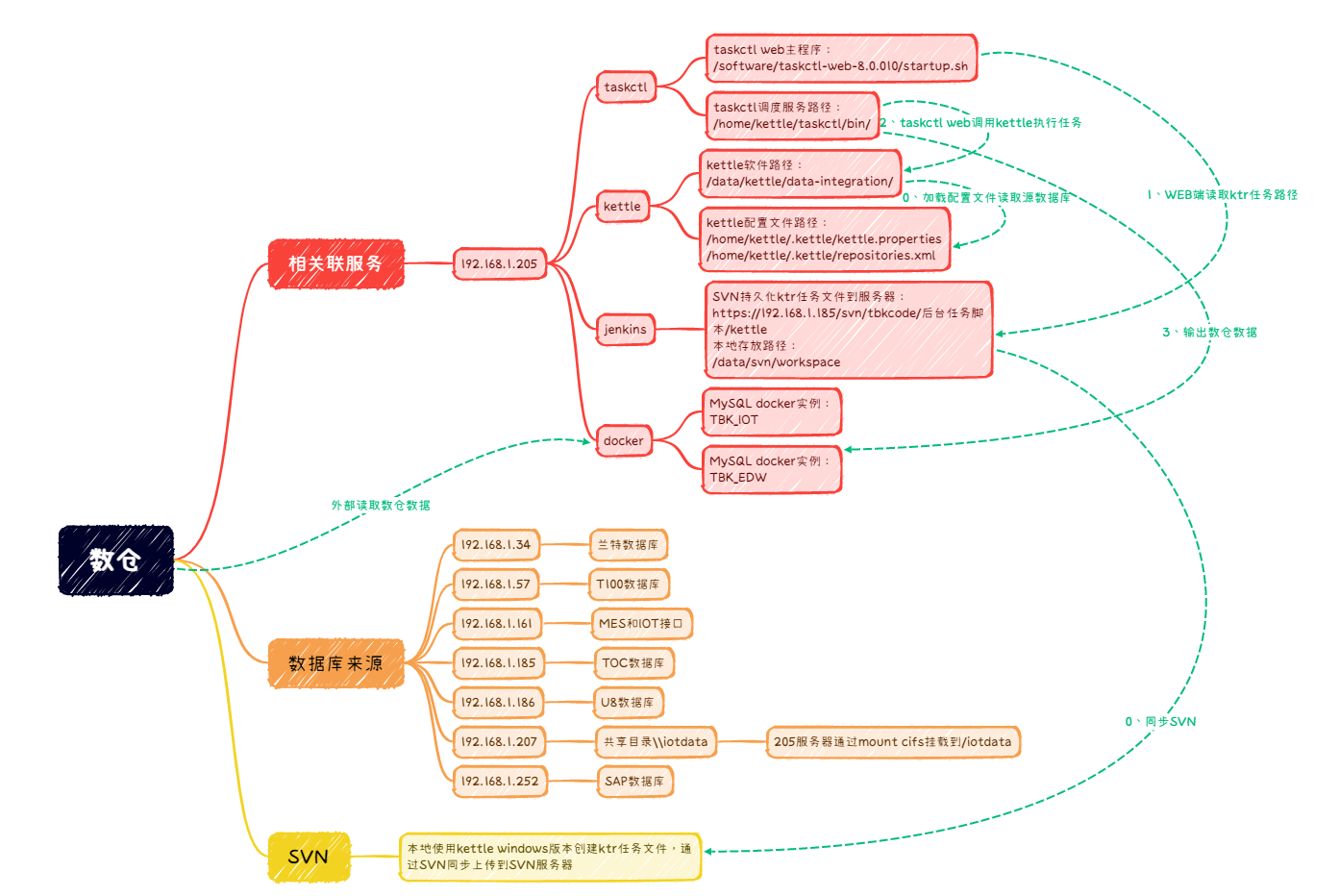
部署好taskctl和kettle基本参数后,基本上就是配置数据来源和编辑ktrjob
在windows下使用kettle软件编辑好ktr或kjob后,通过svn同步到服务器,然后使用jenkins持久化同步到taskctl服务器
编辑/home/kettle/.kettle/kettle.properties文件来配置数据源,其中可以配置scada的iot数据:如收集几台日志到日志服务器,然后设置共享,taskctl通过挂载共享来读写日志文件:mount.cifs -o username=administrator,uid=1000,domain=fstbk.com \\192.168.7.22\iotdata\ /p2ldata
1、如果共享共享服务器加入了域,则需使用域和域用户
2、使用uid参数来映射用户属性,这样就不会有权限问题了。